Part 7 — Agentic Patterns and the Accuracy Flywheel
How does an agent self-correct after retrieval and generation, and how does the system get more accurate the longer it runs in production?
12 min · Updated June 2026
7.1 Why agents earn their cost
R1–R9 are feed-forward optimizations: they maximize the probability of having the right context in hand before generating. They are necessary but not sufficient, because retrieval quality is not fully knowable before retrieving, and answer quality is not fully knowable before generating.
The residual failure cases after R1–R9 are precisely the cases that require an agent: a component that observes the current state, grades the quality, and decides the next action. The cost (additional LLM calls, latency, API spend) is real. The design principle is that cost is applied selectively: the cheap router (A1) prevents expensive patterns from running on queries that do not need them, and a bounded reflection budget (A6) prevents correction loops from running indefinitely.
7.2 The seven agentic accuracy patterns
A1 — Adaptive RAG router
Failure mode killed: F8 — wrong-tool routing
The entry node of the graph classifies the query before any retrieval occurs. It routes to: no-retrieval (the LLM can answer from parametric memory alone); single-hop retrieval; multi-hop iterative retrieval; GraphRAG (only for confirmed multi-hop or narrative queries); SQL (numeric or aggregation); real-time web search (temporal). This classification runs on a cheap model to minimize cost. The critical benefit: GraphRAG is gated behind this classifier. Without A1, applying GraphRAG to simple factoid questions actively degrades accuracy by approximately 13% (empirically established).
A2 — CRAG: Corrective Retrieval Augmented Generation
Failure modes killed: F6 — distractor poisoning; F7 — no-answer / stale
After retrieval and before generation, a grade_documents node scores each retrieved chunk for relevance to the specific query. Chunks that score “not relevant” are filtered. If the filtered set is empty, the conditional edge routes to query transformation or web-search fallback rather than proceeding to generation.
# CRAG core: grade_documents node + conditional edge
workflow.add_node("retrieve", retrieve_node)
workflow.add_node("grade_documents", grade_documents_node)
workflow.add_edge("retrieve", "grade_documents")
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"web_search": "web_search",
"generate": "generate",
},
)A3 — Self-RAG: generation verification loop
Failure modes killed: F5 — lost-in-the-middle; F6 — distractor poisoning; F7 — no-answer
After synthesis, a grade_generation node assesses the generated answer along two dimensions: (1) is it supported by the retrieved context (faithfulness)? (2) is it useful— does it actually answer the question (relevancy)?
workflow.add_conditional_edges(
"generate",
grade_generation_v_documents_and_question,
{
"not supported": "generate", # Hallucination: regenerate
"not useful": "transform_query", # Correct but irrelevant: re-retrieve
"useful": END, # Quality gate passed
},
)The key insight: the system can now detect and label its own hallucinations in production. Every “not supported” edge traversal is a detected hallucination event — a trace that should enter the human-review queue.
A4 — Query decomposition and parallel fan-out
Failure mode killed: F4 — multi-hop failure
A planner node splits a compound question into atomic sub-queries, each independently retrievable. LangGraph’s Send API distributes sub-queries to parallel retriever nodes. A join node fuses results with RRF before reranking.
def parallel_retrieve(state: GraphState) -> list[Send]:
return [
Send("retrieve_subquery", {"query": q, "tenant_id": state["tenant_id"]})
for q in state["sub_queries"]
]
workflow.add_conditional_edges("planner", parallel_retrieve, ["retrieve_subquery"])
workflow.add_node("fuse_results", rrf_fusion_node)A5 — Mandatory grounded citation
Failure modes killed: F6, F7; makes F5 auditable
Synthesis is constrained to produce a citation (chunk_id, source_uri, page) for every factual claim. Forcing citation attribution raises faithfulness structurally by making the constraint explicit in the synthesis prompt, and makes every failure traceable — a wrong cited claim is auditable; an uncited claim is not.
A6 — Bounded reflection budget
Failure mode prevented: runaway loops and cost blow-up
The Self-RAG and CRAG correction loops are recursive. LangGraph’s recursion_limit parameter bounds the maximum number of correction iterations. After the budget is exhausted, the system returns a hedged answer rather than spinning indefinitely.
A7 — Tool-use fallback
Failure mode killed: F7 — stale / missing content
When CRAG (A2) determines that the corpus is insufficient, it invokes a real-time tool rather than hallucinating. The MCP tool registry provides: web_search (current events), sql_query (exact numeric lookups), http_fetch (live API endpoints), asr_transcribe (on-demand audio transcription). The knowledge base is not the only source of truth, and the agent architecture allows seamless handoff to external tools when the corpus’s limits are reached.
7.3 The complete LangGraph graph structure
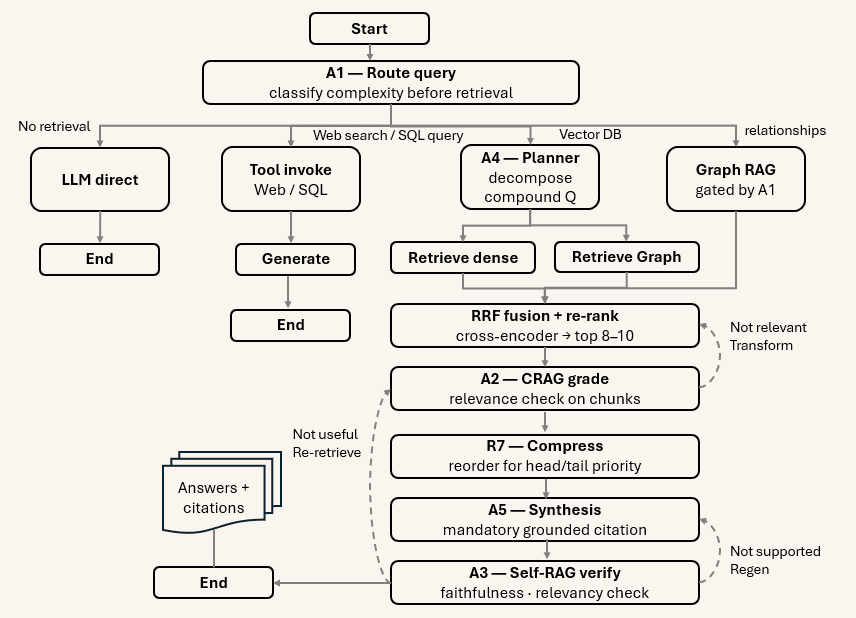
This graph is not a pipeline. A pipeline has one path. This graph has multiple conditional paths, loops with termination conditions, and parallel branches. The accuracy it achieves is precisely because it can observe intermediate results and change course.
8.1 The three observability functions
Patterns are only as good as their ability to improve over time. A static system that does not learn from its failures will decay as the corpus changes, as query distributions shift, and as the organisation’s information needs evolve. The observability and human-review architecture creates a compound accuracy flywheel: the system produces traces, traces are evaluated, failures are reviewed, reviews become golden data, golden data improves the system, the improved system produces better traces.
Function 1 — Real-time correction triggers. Every CRAG grading decision, every Self-RAG faithfulness failure, every routing decision is emitted as an OTel span. When the faithfulness score drops below threshold, an alert fires. When CRAG fires repeatedly on the same query class, a human-review job is queued.
Function 2 — Systematic pattern detection. Individual failures are noise. Patterns of failures are signal. Langfuse surfaces the aggregate: which query patterns consistently fail faithfulness? Phoenix visualizes embedding-space clusters that consistently retrieve poorly — making the topological structure of the failure space visible, not just individual instances.
Function 3 — CI regression enforcement. Every model upgrade, embedding-model change, or prompt modification runs against the golden dataset. DeepEval and Ragas provide quantitative evaluation against the current baseline. Accuracy is maintained automatically rather than hoped for manually.
8.2 Failure mode to metric to action
| Failure mode | Primary metric | Human action when triggered |
|---|---|---|
| F1 Semantic gap | Context recall@k | Tune RRF weights; add query-expansion rules |
| F2 Lexical miss | BM25-recall vs. dense-recall split | Confirm BM25 indexing for that term class |
| F3 Top-k cliff | MRR, NDCG@10 | Tune reranker top-k and score threshold |
| F4 Multi-hop | Multi-hop answer accuracy | Tune decomposer prompt; expand graph KG for that domain |
| F5 Lost-in-middle | Faithfulness vs. chunk position | Tune reordering in R7 |
| F6 Distractor poisoning | Faithfulness, relevance of top chunk | Raise reranker score floor in R9 |
| F7 No-answer | No-answer accuracy on unanswerable set | Review R9 threshold; expand web-search fallback triggers |
| F8 Wrong-tool routing | Routing accuracy | Augment classifier training set; re-run DSPy |
| Hallucination (A3 fires) | not_supported edge traversal rate | Human reviews trace in Argilla; adds to golden set |
| Ingestion degradation | extraction F1 vs. golden | Block the pipeline change; investigate parser issue |
8.3 The compound accuracy flywheel
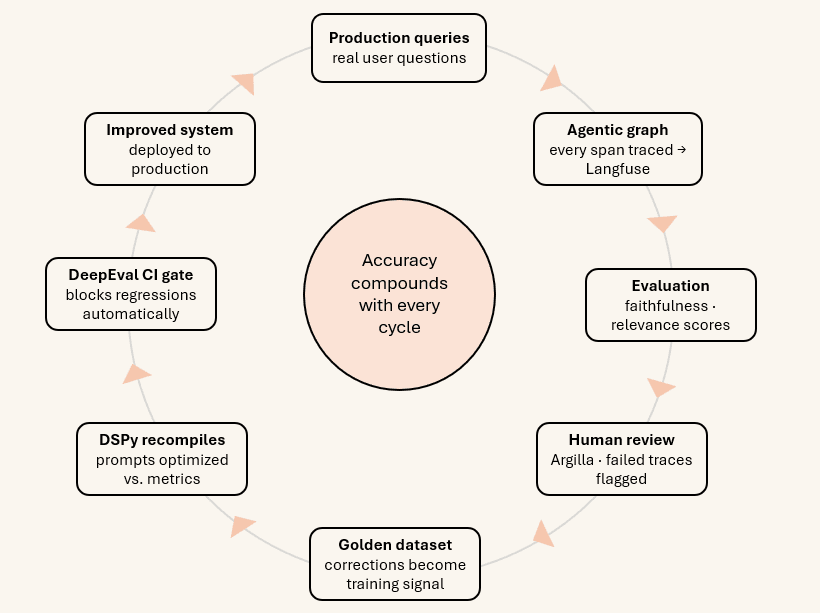
Accuracy improves in production — not from engineering effort at deployment time, but from the structural loop between the system’s own uncertainty signals and the human knowledge that corrects them.