Part 2 — What Is Multimodal Hybrid Agentic RAG?
What do those four words actually mean, and which problem does each one solve?
8 min · Updated June 2026
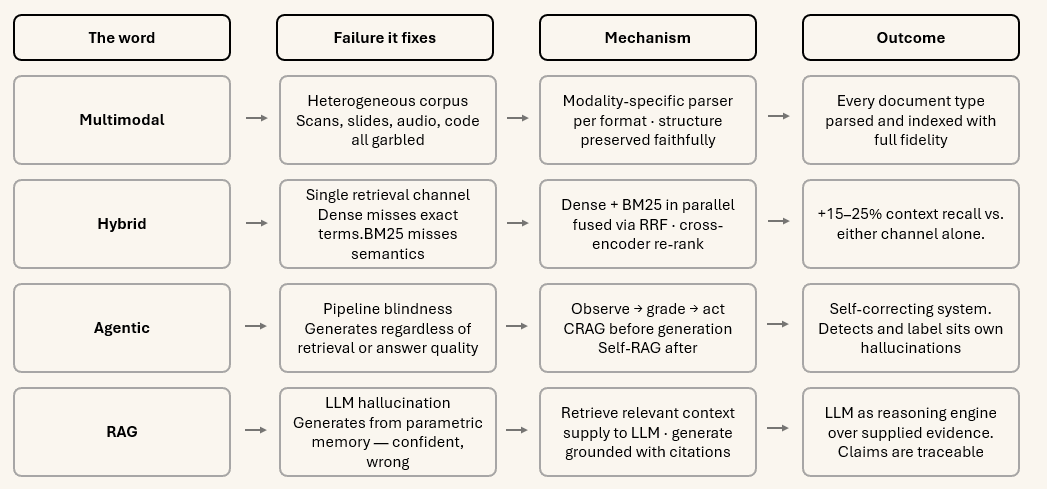
The name carries four independent concepts, each addressing a distinct failure mode. Understanding them separately before combining them is essential.
2.1 Multimodal
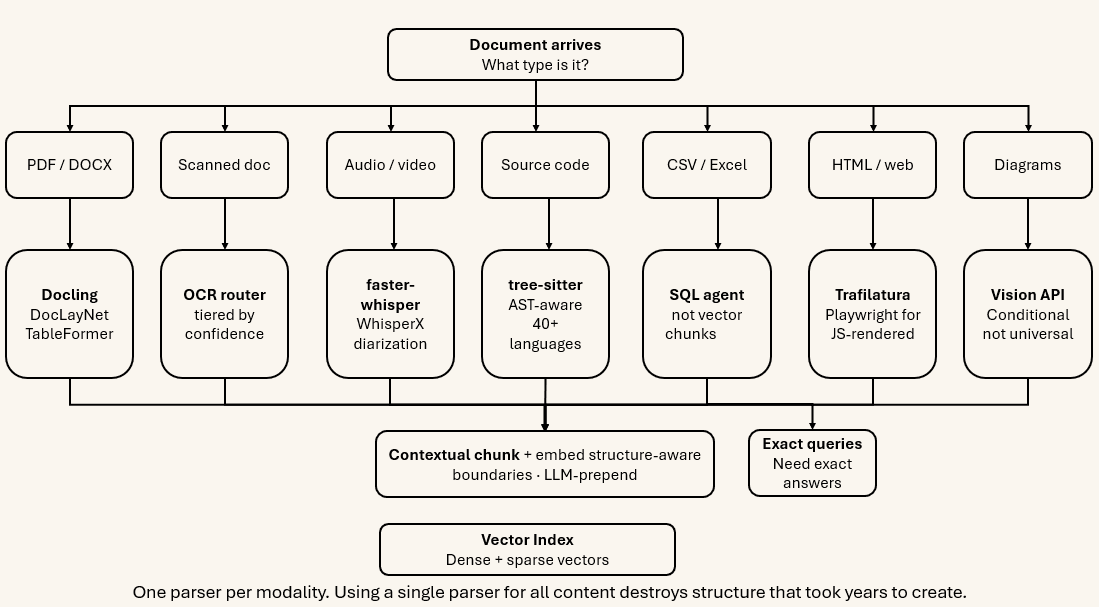
An enterprise knowledge base is not a collection of clean text files. It is a heterogeneous corpus:
- Digitally-born PDFs and DOCX files— reports, contracts, policies, often with complex layout, multi-column structure, embedded tables, and mathematical formulas.
- Scanned documents— legacy archives, signed contracts, physical records, anything that went through a photocopier.
- Presentation slides— diagrams, infographic-style layouts, text embedded in shapes that a text extractor cannot parse.
- Audio and video— earnings calls, design review recordings, training videos, customer support calls.
- Source code— internal libraries, API documentation, configuration files.
- Structured data— spreadsheets, CSV exports, database tables, financial models.
- Web content— dynamic HTML pages, intranet portals, product documentation sites.
- Visually rich documents— engineering drawings, medical imaging reports, financial charts.
A multimodal system does not convert everything to text and pretend it is all the same. It parses each modality faithfully using the right tool for that format, preserves structure (tables as grids, not as flat strings), links related content across modalities, and represents each element in a vector space appropriate for retrieval.
2.2 Hybrid
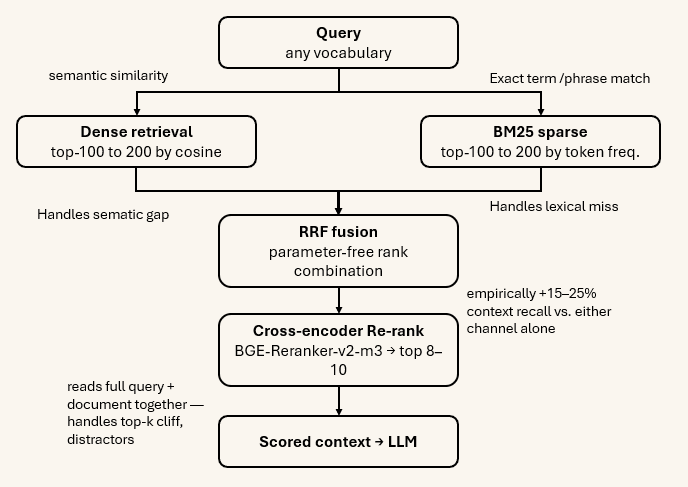
Hybrid refers specifically to retrieval— the combination of multiple complementary retrieval signals fused at query time.
Dense retrieval(embedding similarity) excels at semantic generalisation. A question about “declining quarterly performance” retrieves documents containing “revenue dropped,” “earnings shortfall,” “profit contraction.” It handles paraphrase, synonym, and concept-level matching.
Sparse retrieval(BM25 / keyword matching) excels at exact-term recall. A query for “ISO 27001 Clause 9.4.2” or “part number XR-7741” will not be paraphrased. The document either contains those tokens or it does not. Dense retrieval can miss them entirely; BM25 will find them.
Hybrid retrievalruns both channels over every query and fuses the ranked results using Reciprocal Rank Fusion (RRF) — a parameter-free algebraic combination that has been shown empirically to outperform either channel alone on almost every benchmark. The research finding is unambiguous: blended beats either alone. In some configurations the improvement in context recall is 15–25%.
After retrieval comes reranking: a cross-encoder model that reads the full query and each retrieved document together — much more computationally expensive than retrieval, but much more accurate — and re-orders the top candidates from coarse similarity to fine relevance. This two-stage pattern (retrieve wide, rerank precisely) recovers most of the precision that coarse vector search sacrifices for speed.
2.3 Agentic
A pipeline executes a fixed sequence of steps regardless of the query. An agent observes the current state, decides what action to take next, executes it, observes the result, and decides again. The critical insight is that retrieval quality is not knowable before retrieving — and answer quality is not knowable before generating. A pipeline cannot self-correct. An agent can.
Agentic patterns in RAG implement three classes of self-correction:
- Before retrieval:route the query to the right strategy — flat vector search for simple factoids, graph traversal for multi-hop, real-time web search for temporal queries, SQL for exact numeric queries.
- After retrieval, before generation: grade whether the retrieved context is actually relevant. If it is not, re-retrieve, transform the query, or invoke a fallback.
- After generation: verify whether the generated answer is faithful to the retrieved context. If it is not, flag as a hallucination and regenerate or re-retrieve.
Each of these corrections costs additional LLM calls. The accuracy gains are substantial and empirically well-established. A calibrated system applies corrections selectively — not every query needs a three-stage verification loop — which is itself an agentic decision.
2.4 RAG (Retrieval Augmented Generation)
The foundational pattern: retrieve relevant context from the knowledge base, supply it to the language model as part of the prompt, and generate an answer grounded in that context with citations to source documents. The LLM is a reasoning engine over supplied evidence, not a source of facts.
The combination — multimodal ingestion, hybrid retrieval, agentic orchestration, and grounded generation — is not an incremental improvement over first-generation RAG. It is a different class of system: one that is aware of its own uncertainty, structured to recover from its own failures, and designed to be more accurate in production than it was on day one.