Part 5 — The economics of the harness
Can I justify the spend — and what does it cost to run AI coding at scale?
5 min · Updated June 2026
Parts 2–4 showed you what the harness is made of. Before you spend a quarter building it, you need the argument that gets that quarter approved. The conversation about AI coding usually starts and ends with developer velocity — how fast can we ship? For anyone signing the budget, the real metric is total cost of ownership, and in the AI era that cost is dominated by one thing: tokens.
5.1 — My leadership thinks adopting AI coding is just a tooling purchase. How do I reframe it as the CapEx-vs-OpEx decision it actually is.
Every workflow shifts cost between two buckets. CapEx is the upfront investment to build something — designing schemas, writing tests, structuring context, standing up the harness. OpEx is the ongoing cost to run, fix, and maintain it — and in 2026, OpEx is overwhelmingly the token economy: every prompt, every retry, every agent loop is metered.
The two ends of the Q1.1 spectrum have opposite cost shapes, and naming them is how you frame the budget conversation.
Vibe coding is low CapEx, high OpEx. The barrier to entry is essentially zero — a subscription and a few prompts. But the bill compounds three ways:
- Token burn. Dumping unstructured files into the context window and repeatedly asking the model to fix its own unverified mistakes creates an expensive prompting loop with low first-pass success. The ETH Zurich result from Q1.4 — 20%+ cost increase from bloated context — is this tax, measured.
- Maintenance tax. Code from ad-hoc prompting lacks structural consistency. Six months later, an engineer spends days reverse-engineering AI-generated spaghetti.
- Security remediation. Without an evaluation harness, fast code generation means fast vulnerability generation. Fixing a flaw in production costs far more than catching it at design time.
Agentic engineering is high CapEx, low OpEx. You invest engineering time upfront — schemas, deterministic test suites, and above all structured context — before a line of production code is generated. The marginal cost of shipping and maintaining each feature then drops sharply, because the AI operates inside a governed factory: its output is structurally sound, pre-tested, and aligned to your standards.
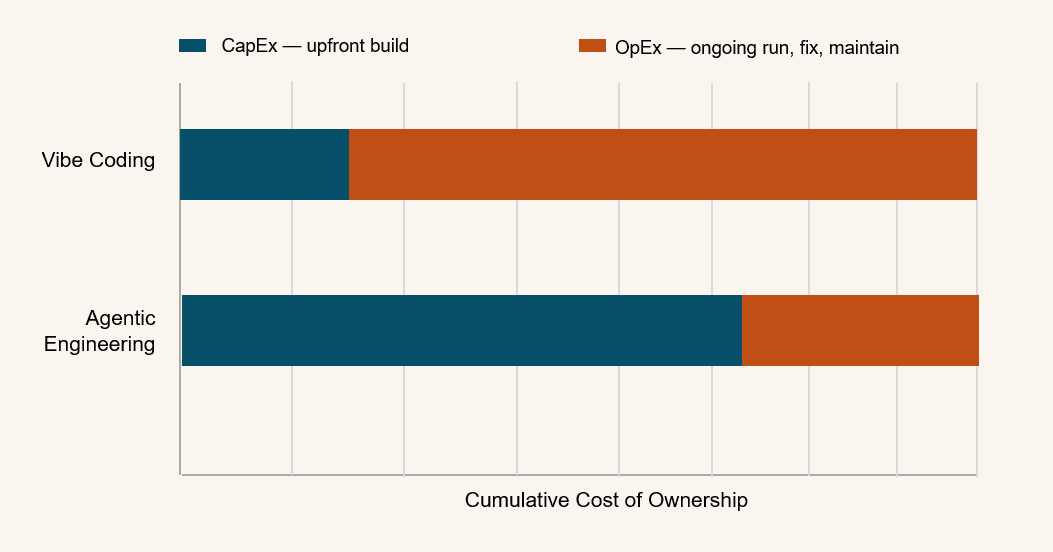
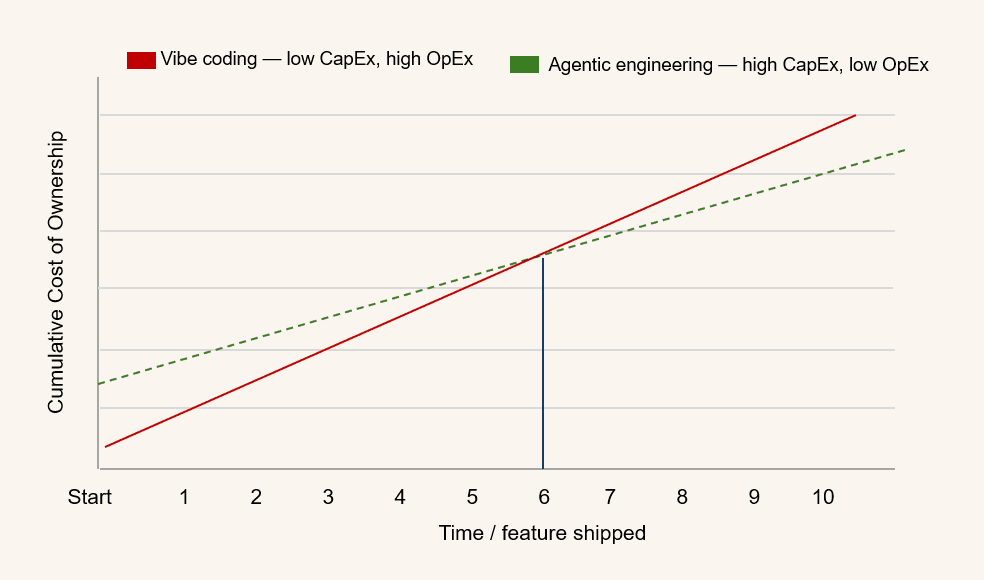
The honest version of the pitch to leadership: there is a crossover. Early on, vibe coding is genuinely cheaper and faster to first output. Past a certain volume and lifespan of code, it costs multiples more per feature than agentic engineering — the maintenance and remediation tax catches up and keeps compounding. The harness is the CapEx you pay to move the crossover in your favor. For disposable code you never cross it; for systems you depend on, you cross it fast.
5.2 — I have to get a quarter of platform investment approved by Senior Delivery Leader and need the argument tight. How do I frame the spend in a way that lands?
Three sentences, in this order:
- 1.“AI doesn’t make our engineers faster by default — the strongest study shows it can make them 19% slower against complex code (METR, 2025). It makes them faster only inside a structured environment.”
- 2.“That environment is a platform investment: weeks to months of one team’s time, then ongoing maintenance — CapEx.”
- 3.“In return, the per-feature operating cost drops and keeps dropping, because we stop paying the token-burn, maintenance, and security-remediation taxes that ungoverned AI use generates.”
Then point at the harness backlog (Part 7) as the line-item. You’re not asking for a tool budget; you’re asking for a platform investment with a measurable OpEx return. Measure that return on cycle time, time-to-productive-contribution, and incident resolution — not lines of code, which AI makes meaningless.
5.3 — I knew lean context files were about correctness, but I'm told they affect cost too. How context engineering becomes a financial lever.
Yes — this is the part most teams miss. In the token economy, a lean context file isn’t just a correctness decision (Q1.4); it’s a cost decision. LLMs charge for every token you send, on every step. Passing a 100,000-token repository into every prompt is financially unviable at scale, and — per the ETH Zurich evidence — it doesn’t even help correctness.
Effective context engineering means the model receives a dense, high-signal payload (a precise AGENTS.md, the right architectural guardrails) rather than a sprawling one. By supplying the right context up front, you raise the agent’s first-pass success rate and avoid the costly trial-and-error loops that define vibe coding. Every retry you prevent is OpEx you don’t spend. The progressive-disclosure model from Q1.5 is the mechanism: you pay for the one skill the agent is actively using, not the forty it isn’t.
5.4 — Beyond trimming context, I want to know what else I can pull to bring my running token costs down. What are the other OpEx levers?
Two, both of which the harness makes possible.
Intelligent model routing. In a vibe-coding workflow, a developer pays premium frontier-model token prices for everything — including asking the AI to fix a typo or write a trivial unit test. A well-designed factory routes by complexity: large advanced models for requirements, architecture, and initial implementation; smaller, faster, cheaper models for deterministic, lower-complexity work like test generation, code review, and CI monitoring. Orchestrating a multi-model ecosystem holds output quality while systematically cutting the operational token bill. On Claude Code you pin this per subagent and via the CLAUDE_CODE_SUBAGENT_MODEL environment variable (Part 2); the model-pinning discipline from Part 2 is what makes routing auditable.
Dynamic context and skills. The same progressive disclosure that controls correctness controls spend. Skills and MCP tool-calling load specialized knowledge only on demand, so the token cost of a deep capability library is paid only when a capability is used. This is covered in detail in Part 6 — three-layer knowledge encoding and AST-based search are the technical mechanisms behind this financial lever.
5.5 — Before I roll this out, I want to know how the economics blow up so I can price it in. What are the financial failure modes to plan for?
Two failure modes worth pricing in before rollout (both expanded in Part 8):
- Subagent token multiplication. Subagent-heavy workflows can run roughly 7× the tokens of a single-threaded session. Powerful, but stand up per-team cost dashboards before the first surprised finance conversation, not after.
- Rate limits as a hidden ceiling. Default frontier-model rate limits (e.g., Bedrock Opus around 25 RPM) will throttle a team rollout if you don’t raise them ahead of time. A cost ceiling you discover during rollout is an outage.
The throughline: the harness isn’t only how you make AI safe. It’s how you make it economical. The same lean context, the same governed factory, the same routing discipline that produce reliable code also produce affordable code. Structure scales; vibes bill by the token.
Next: the technical mechanisms behind these financial levers.
Part 6 — Encoding domain knowledge →How do we encode what our org actually knows — and stop the agent from grepping everything?