How Do You Stop Agents from Doing Dangerous Things?
How do we prevent agents from taking unauthorized or dangerous actions -- not just detect them afterward?
7 min · Updated June 2026
Article 4 of 6 — “Governing AI Agents in the Enterprise: A Practical Architecture Guide”
This article covers preventive governance: the controls that stop an agent from taking an unauthorized, dangerous, or cascading-failure action — before it happens, not after. It covers four questions: policy enforcement, agent identity, execution sandboxing, and reliability engineering.
Q4.1 -- How do we stop an agent from taking a dangerous or non-compliant action in the first place -- not just detect it afterward?
The pattern: Runtime policy enforcement at the action boundary.
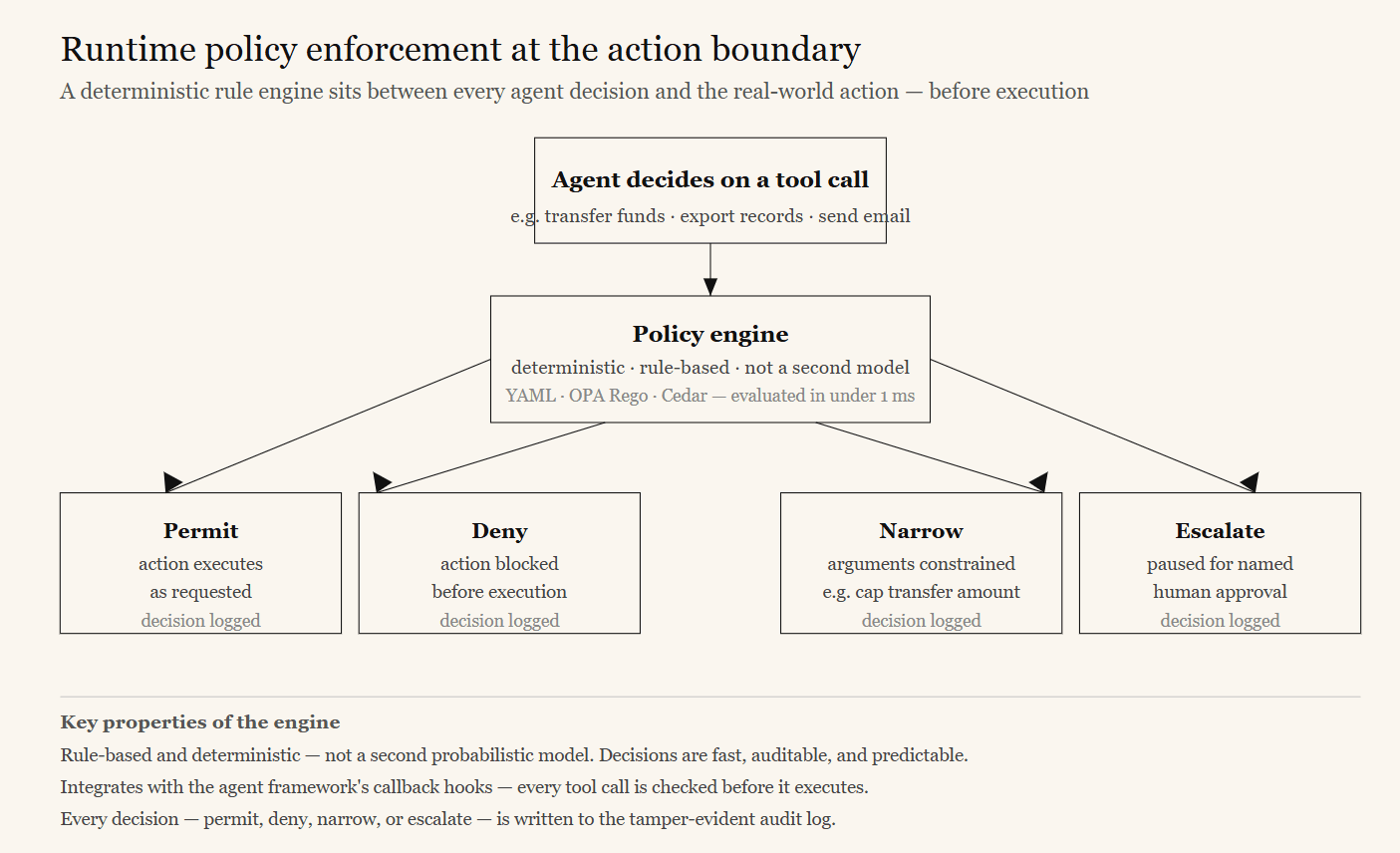
Evaluation and telemetry are largely detectivecontrols — they tell you something went wrong, often after it did. For high-consequence actions you need a preventivecontrol: a deterministic policy engine that sits between the agent’s decision and the real-world action, and that can permit, deny, narrow, or escalate for approval before the action executes.
Critically, this enforcement must be rule-based and deterministic — you do not want a second probabilistic model deciding whether the first one is allowed to act. Policy decisions need to be fast (well under a millisecond), auditable, and predictable.
A tool like the Microsoft Agent Governance Toolkit (AGT) provides a policy engine where policies are written declaratively — in YAML, OPA Rego, or Cedar — and evaluated against every tool invocation. The engine integrates with an agent framework’s callback hooks, so every tool call is checked against policy before it executes. A policy can outright deny an action, require human approval for it, rate-limit it, or constrain its arguments. Each decision is recorded in the audit log.
A representative policy: deny any database tool call whose query contains a destructive keyword; require named human approval before any tool that sends data externally if the payload contains personal data; rate-limit the web-search tool per agent instance.
Real-world examples
Banking -- payments and wire agent
Policy denies any outbound transfer above a threshold without dual human approval, and denies transfers to beneficiaries not on an allow-list. Even if the agent is socially engineered or hallucinates a transfer instruction, the action is blocked at the boundary — the agent never had the unsupervised authority to move the money.
Healthcare -- patient-records agent
Policy enforces minimum-necessary access: the agent may read only records for the patient in the current authenticated context. Any tool that would export protected health information requires explicit approval. A prompt-injection attempt to make the agent dump other patients’ records fails because the policy — not the model — governs the data tool.
Public sector -- benefits-determination agent
Regulation forbids a fully automated final decision on certain benefit types. Policy intercepts the “finalize determination” tool and routes those case types to a caseworker for sign-off, while letting the agent fully process routine cases — keeping a human in the loop exactly where the law requires one.
Q4.2 -- We have a swarm of agents and sub-agents. How do we know which agent did what, and on whose authority?
The pattern: Cryptographic agent identity and inter-agent trust.
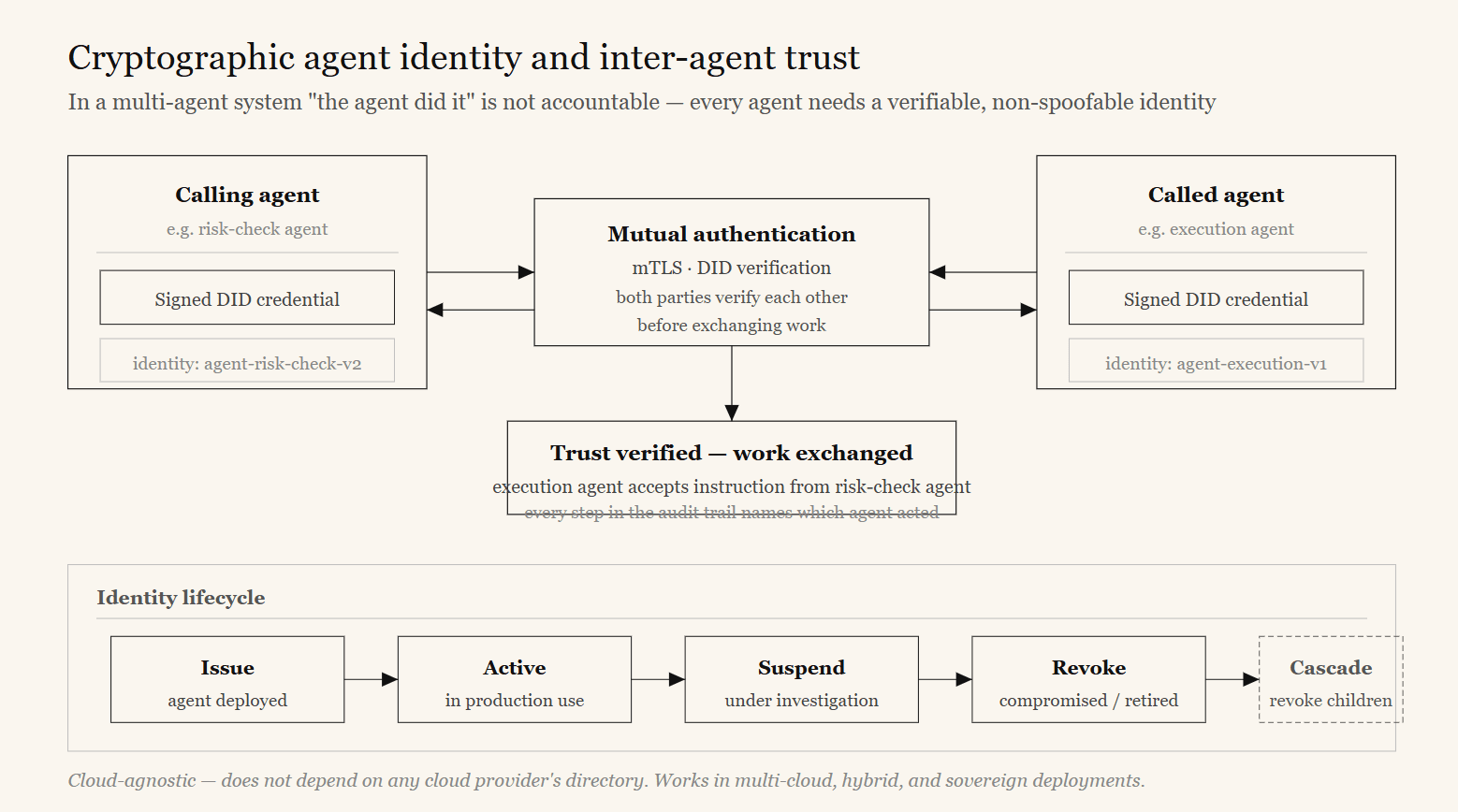
In a multi-agent system, “the agent did it” is not an accountable statement — there are many agents, they call one another, and they act on behalf of different users and systems. Each agent needs a verifiable, non-spoofable identity, and inter-agent calls need mutual authentication, so that every action can be attributed to a specific agent acting under a specific authority.
The AGT identity module gives each agent a cryptographic identity — a decentralized identifier signed with strong keys — and supports mutual TLS between agents. An inter-agent trust protocol lets a calling agent and a called agent verify each other before exchanging work. Identities have a lifecycle: they can be issued, suspended, and revoked, including cascade revocation if a parent identity is compromised.
This identity stack is cloud-agnostic — it does not depend on any cloud provider’s directory — so it works in multi-cloud, hybrid, and sovereign deployments.
Real-world examples
Capital markets -- multi-agent trade workflow
A research agent, a risk-check agent, and an execution agent collaborate on a trade. Cryptographic identity plus mutual authentication ensures the execution agent will only accept a trade instruction from the genuine, currently-valid risk-check agent — not a spoofed or stale one. Every step in the audit trail names exactly which agent acted.
Supply chain -- procurement and logistics agents
A procurement agent at one business unit calls a logistics agent at another. The inter-agent trust protocol verifies both parties and the scope of the request before any purchase commitment is made, preventing a rogue or impersonated agent from injecting fraudulent orders.
Enterprise IT -- IT-operations agents
Dozens of automation agents act across infrastructure. When one is found to be compromised, its identity is revoked instantly, and cascade revocation invalidates every child agent it spawned — a clean, system-wide containment action rather than a frantic manual hunt.
Q4.3 -- Our agents execute code and call real systems. When one goes wrong, how do we contain the blast radius?
The pattern: Execution sandboxing — isolate what runs.
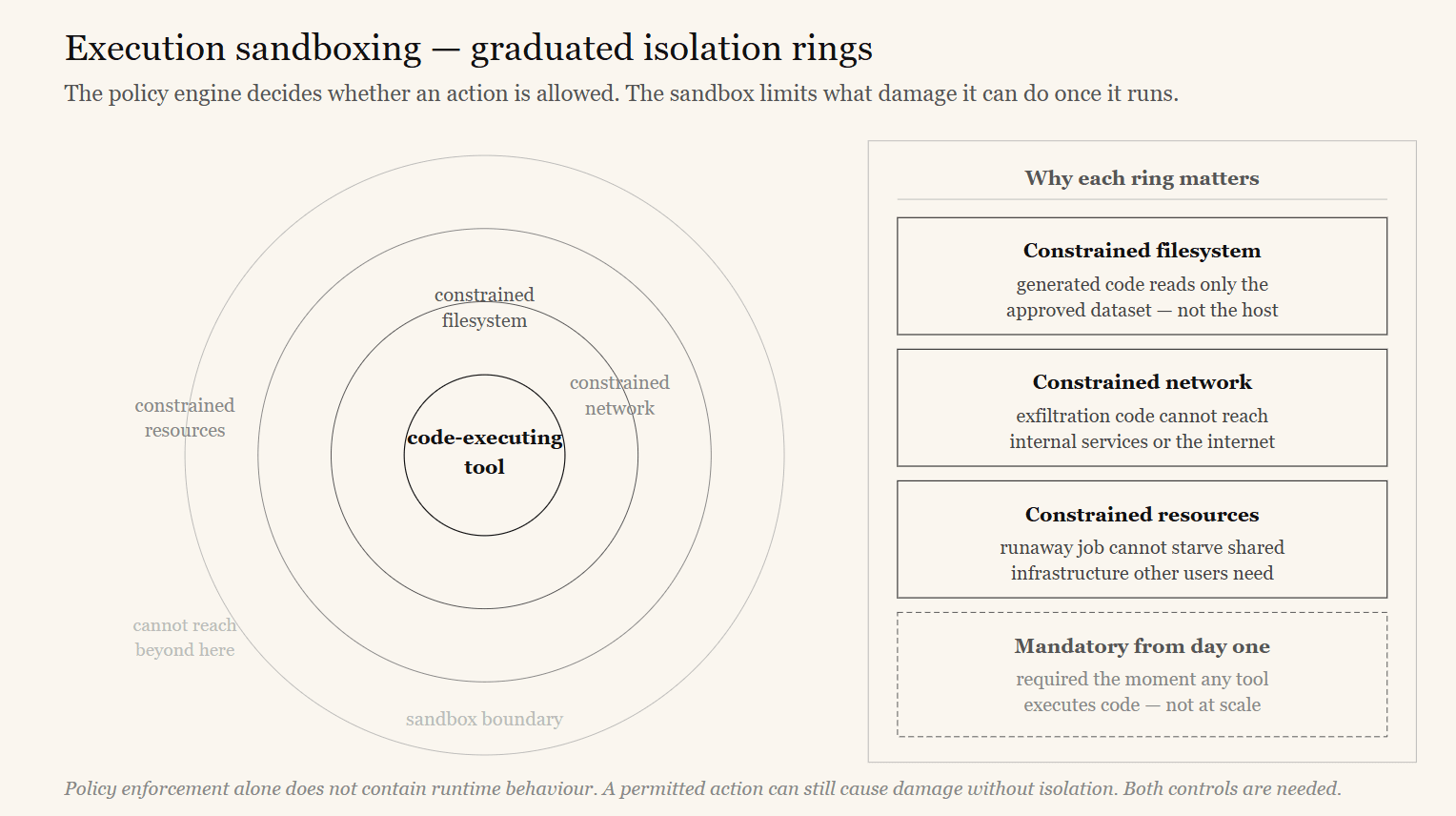
A policy engine decides whether an action is allowed. It does not control what damage that action can do once it is running. If an agent can execute code — through a code-interpreter tool, a shell tool, a Python runtime, or a third-party tool that itself runs code — then a malicious or hallucinated payload that the policy permitted can still read files, open network connections, or consume resources it should not. You need execution isolation.
The AGT runtime module provides layered execution sandboxing — graduated isolation rings — for code-executing tools. Code runs with constrained file-system, network, and resource access, so even a policy-permitted action cannot reach beyond its intended boundary.
This module is mandatory from day one for any agent with a code-executing tool. It is not a scale-up option, because policy enforcement alone does not contain runtime behavior.
Real-world examples
Data and analytics -- code-interpreter agent
A business-intelligence agent writes and runs Python to answer ad-hoc data questions. Sandboxing ensures generated code can only touch the approved dataset — it cannot reach internal network services or the host file system, even if a user crafts a prompt that coaxes the agent into writing exfiltration code.
DevOps -- infrastructure automation agent
An agent generates and applies infrastructure scripts. The sandbox constrains what those scripts can reach, so a hallucinated or injected command cannot escalate from “modify this one resource” to “delete the production environment.”
Pharmaceutical research -- computational chemistry agent
A research agent runs compute-heavy simulation code. Resource isolation prevents a runaway or maliciously crafted job from starving shared scientific computing infrastructure that other researchers depend on.
Q4.4 -- One stuck or looping agent threatens to take down the whole workflow. How do we stop cascading failure and hit an emergency stop?
The pattern: Reliability engineering for agents — circuit breakers, SLOs, and a kill switch.
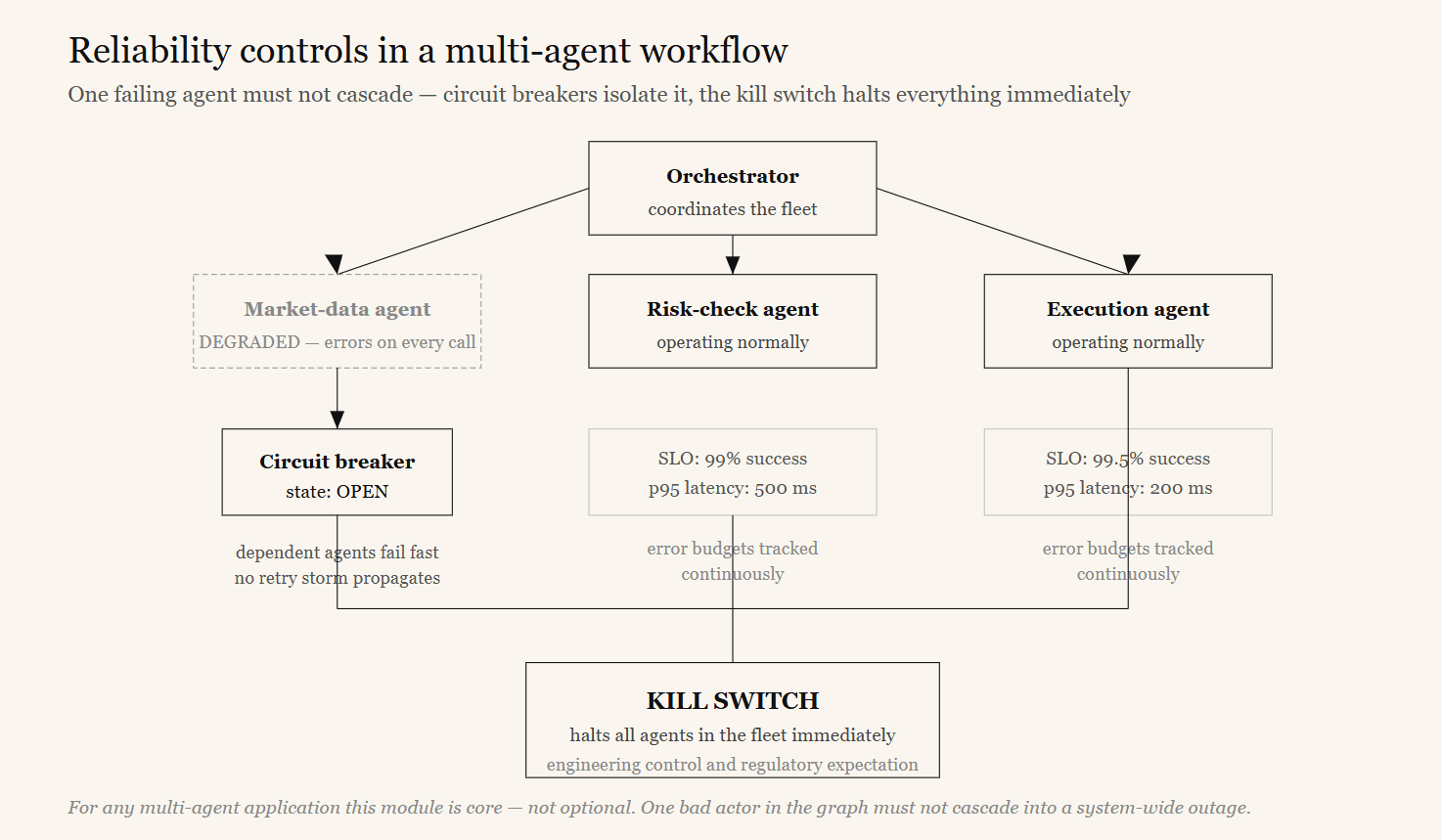
In a multi-agent workflow, one failing, looping, or degraded agent can fan out and exhaust budgets, rate limits, and downstream capacity across the entire system. Agents need the same reliability controls mature distributed systems have: circuit breakers that isolate a failing dependency, service-level objectives that quantify acceptable failure, and — non-negotiably — a kill switch that can halt an agent or fleet immediately.
The kill switch is both an engineering control and increasingly a regulatory expectation.
The AGT reliability module provides circuit breakers between agents, SLO and error-budget tracking, chaos-testing support, and an emergency kill switch. Wired into the agent runner and the transitions between sub-agents, it prevents one bad actor in the graph from cascading into a system-wide outage.
For any multi-agent application, this module is core — not optional.
Real-world examples
Trading -- multi-agent trading desk
A market-data agent starts returning errors during a volatile session. A circuit breaker isolates it so dependent strategy agents fail fast and gracefully instead of all retrying in a storm. The desk-wide kill switch lets a human halt all automated trading instantly if conditions warrant.
Retail -- peak-season order orchestration
On the busiest sales day, a payment-verification agent slows under load. Circuit breakers stop the slowdown from propagating into the order, inventory, and fulfilment agents — preventing a single bottleneck from collapsing the entire order pipeline.
Telecom -- network-operations agents
During a regional incident, automated remediation agents risk amplifying the problem with conflicting corrective actions. Error budgets and the kill switch let operations pause automation and take manual control before automated remediation makes the outage worse.
The distinction that matters
Questions 5 through 8 all live in the governance layer, but they address different threat surfaces:
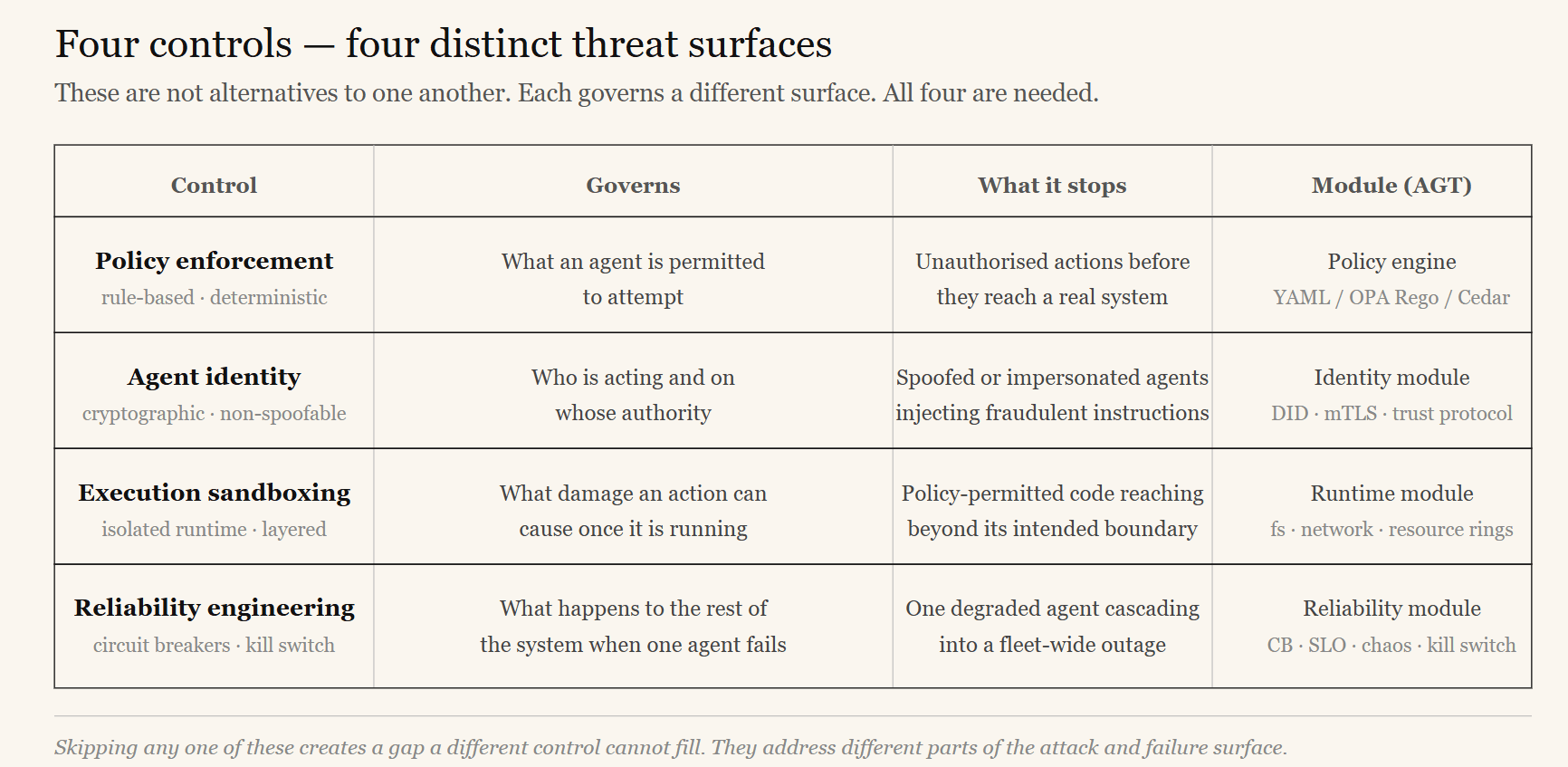
| Control | Governs |
|---|---|
| Policy enforcement | What an agent is allowed to attempt |
| Agent identity | Who is acting and on whose authority |
| Execution sandboxing | What damage an action can cause once it is running |
| Reliability engineering | What happens to the rest of the system when one agent fails |
All four are needed. They are not substitutes for one another. The next article covers the accountability side of governance — how to prove that all of this was in place when a regulator or auditor asks.