How Do You Tie It All Together -- and Where Do You Start?
We cannot build all of this at once. What do we do first, and what can wait?
8 min · Updated June 2026
Article 6 of 6 — “Governing AI Agents in the Enterprise: A Practical Architecture Guide”
This final article answers two closing questions: how to connect evaluation, telemetry, and governance into a single coherent system rather than three disconnected tools — and how to sequence adoption so you build in the right order without skipping controls that are risk-mandatory from day one.
Q6.1 -- How do we connect evaluation, telemetry, and governance so they are not three disconnected silos?
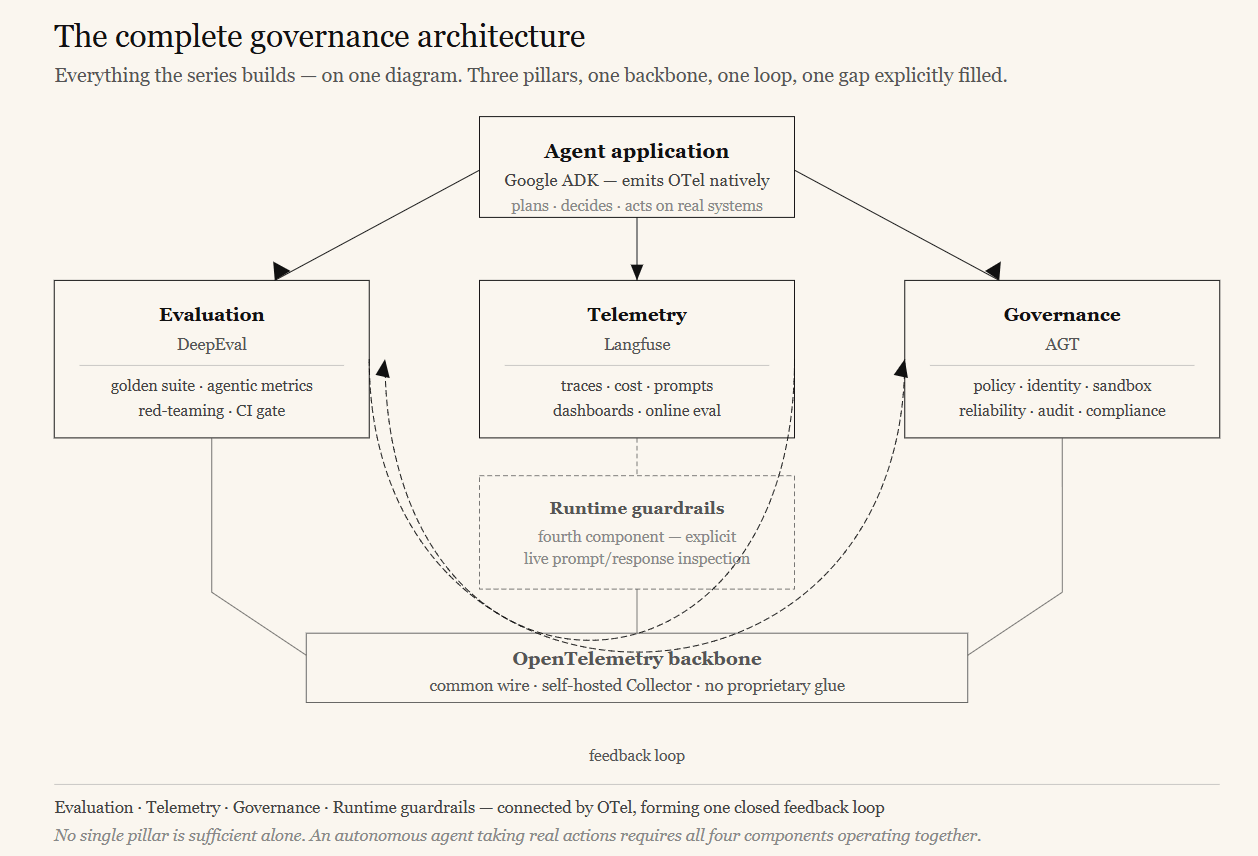
The pattern: OpenTelemetry as the unified backbone, and the continuous-improvement loop.
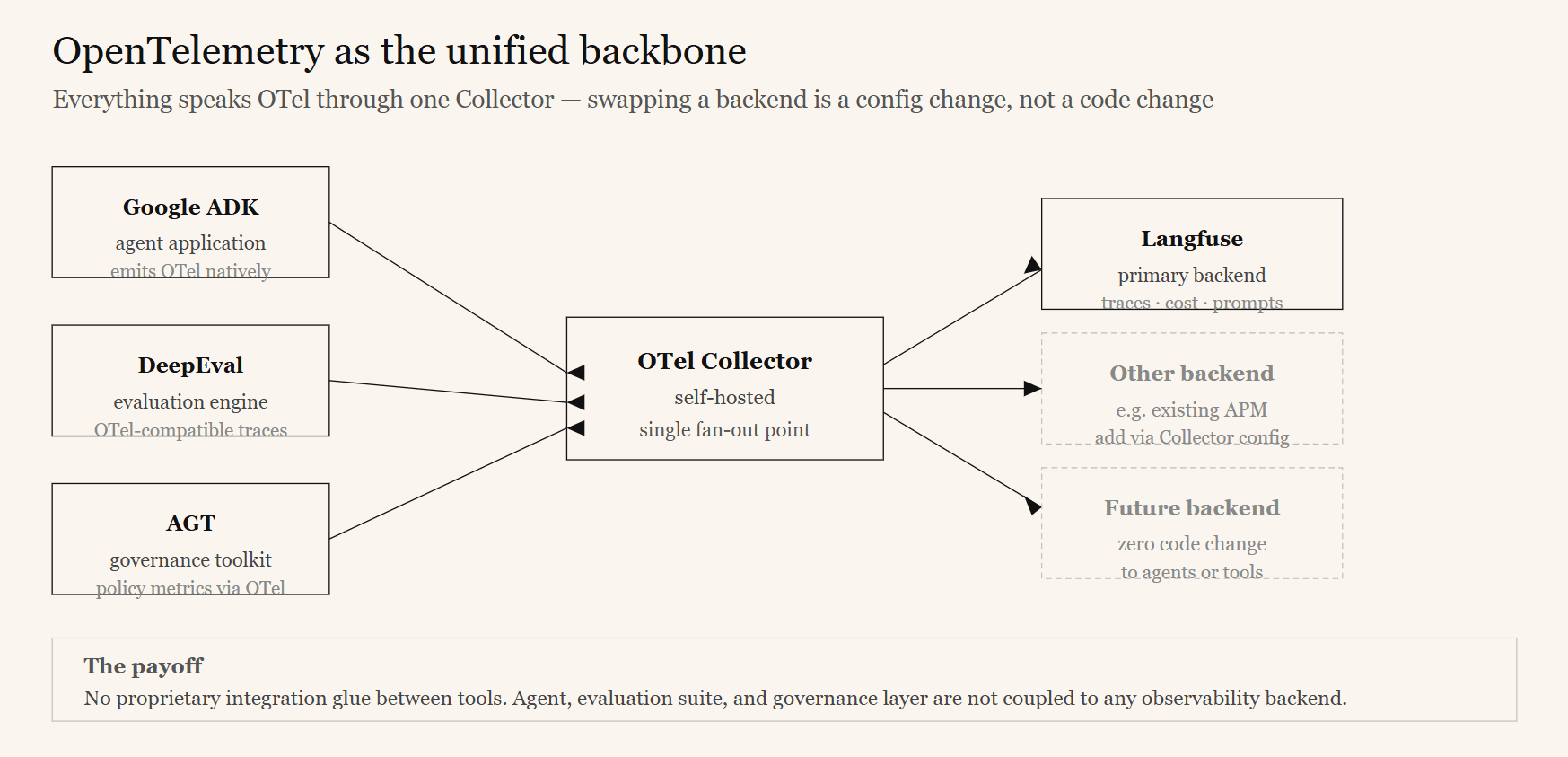
Three best-of-breed tools will become three silos unless something connects them. The pattern that prevents this has two halves: a common data standard so the tools interoperate without custom glue, and a feedback loop so the three disciplines actively improve one another.
The backbone — OpenTelemetry. OpenTelemetry (OTel) is the shared wire. Google ADK emits OpenTelemetry traces natively. Langfuse ingests them through its OpenTelemetry endpoint. DeepEval’s instrumentation produces OpenTelemetry-compatible traces during evaluation. The governance toolkit exports its policy-decision metrics over the same telemetry channels.
Running a self-hosted OpenTelemetry Collector as a single fan-out point makes the backend choice reversible — swapping or adding an observability backend becomes a configuration change, not a code change. No proprietary integration glue is required between the tools.
The loop. This is the key idea from Article 1, now made concrete:
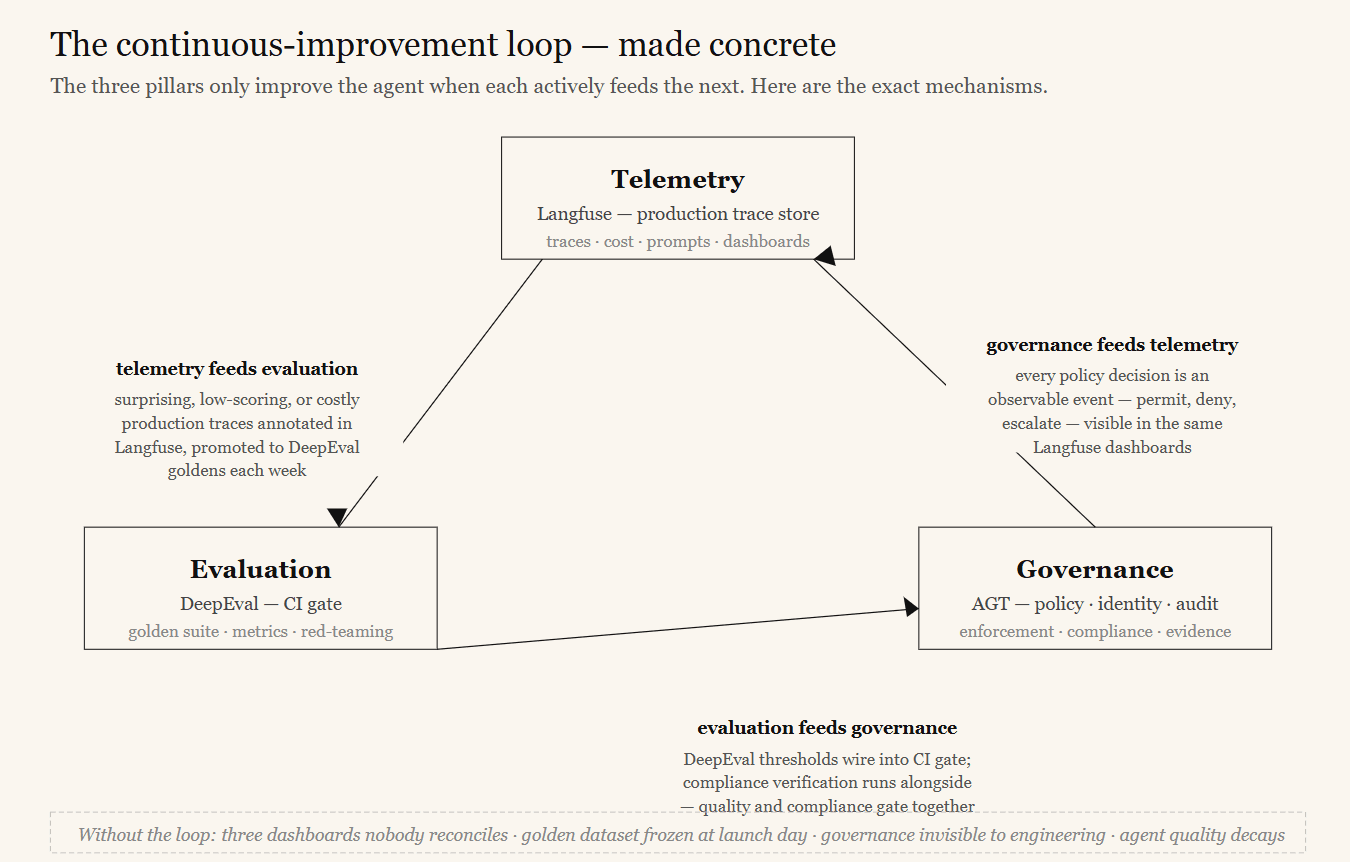
- Telemetry feeds evaluation: Surprising, low-scoring, or costly production traces in Langfuse are promoted into DeepEval golden datasets, continuously enriching the test suite with reality.
- Evaluation feeds governance: DeepEval thresholds are wired into the CI gate, and the governance toolkit’s compliance verification runs alongside them — so quality and compliance both gate releases.
- Governance feeds telemetry: Every policy decision is an observable event in the same dashboards, so governance activity is visible next to quality and cost.
Real-world examples
Insurance
A claims agent produces an unusual trace in production. It is annotated in Langfuse, promoted to a DeepEval golden case, and added to the CI suite — so that exact failure can never silently recur. The loop turned one incident into a permanent regression test.
Retail
A weekly review pulls the lowest-scoring and highest-cost agent traces from Langfuse. The team annotates them, and they become next sprint’s evaluation cases. Agent quality ratchets upward release over release because the feedback loop is an operational habit, not a one-off exercise.
Any team adopting a second observability tool
Because everything speaks OpenTelemetry through the Collector, the organization can add or migrate an observability backend with a configuration change — the agents, the evaluation suite, and the governance layer are untouched.
Q6.2 -- We cannot build all of this at once. What do we do first, and what can wait?
The pattern: Staged adoption sequenced by risk and stack shape — not by convenience.
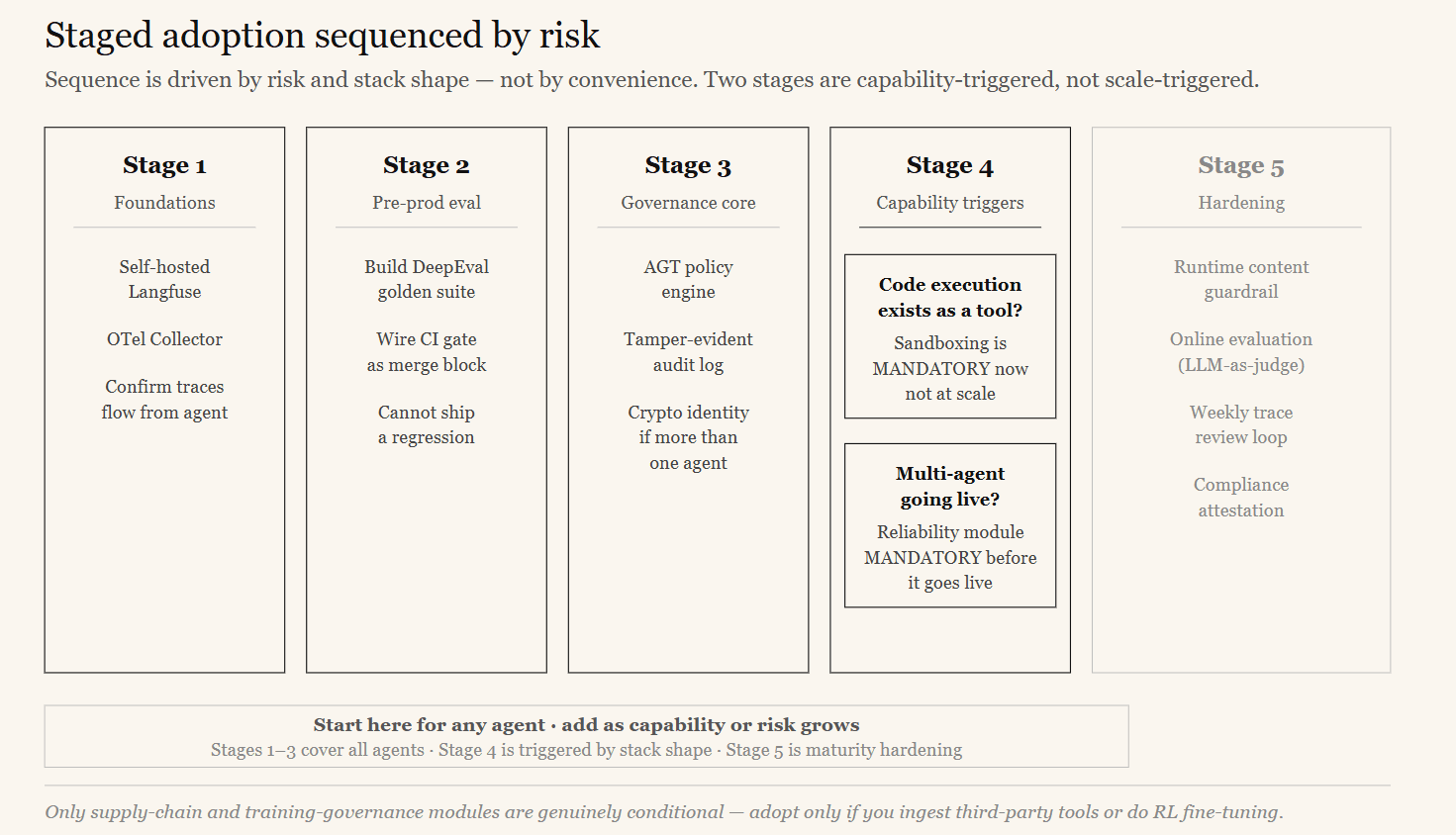
A team cannot stand up evaluation, telemetry, and full governance in week one. But the sequence must be driven by risk, not by what is easiest. Two governance modules are frequently deferred as “scale-up” features when they are actually mandatory the moment a certain capability exists.
The recommended sequence:
- 1.Stage 1 — Foundations. Stand up self-hosted Langfuse and an OpenTelemetry Collector. Confirm traces flow from a trivial agent. You now have visibility— the prerequisite for everything else.
- 2.Stage 2 — Pre-production evaluation. Build the DeepEval golden suite and wire
deepeval test runinto CI as a merge gate. You now cannot ship a regression. - 3.Stage 3 — Governance core. Add the AGT policy engine and tamper-evident audit (these alone cover a large share of agentic risk). Add cryptographic identity once you have more than one agent.
- 4.Stage 4 — Capability-triggered governance. This is where sequencing by risk matters most. If any tool executes code, add the execution-sandboxing module immediately— not at scale, not eventually. It is mandatory from the day code execution exists as a capability. If the application is multi-agent, add the reliability module (circuit breakers, kill switch) immediately— before the multi-agent version goes live. Run compliance verification continuously from the start.
- 5.Stage 5 — Hardening. Add the runtime content-guardrail component; enable online evaluation; establish the weekly trace-review-to-golden feedback loop.
The rule: sequence by risk and stack shape, not by scale. Only the supply-chain and training-governance modules are genuinely conditional — adopt them only if you ingest third-party tools or do reinforcement-learning fine-tuning.
Real-world examples
Energy and utilities -- starting small
A utility begins with a single read-only advisory agent. It needs foundations, evaluation, and the governance policy core — but not yet sandboxing (no code execution) or multi-agent reliability (one agent). The staged model lets it start lean without skipping anything its current risk profile requires.
Manufacturing -- adding capability later
A manufacturer’s quality-inspection agent later gains a code-executing analysis tool. At that moment, execution sandboxing moves from “not applicable” to “mandatory before the feature ships.” The staged model names the exact trigger, so the team does not deploy the new capability ungoverned.
Professional services -- going multi-agent
A consulting firm’s single research agent is expanded into a multi-agent workflow. That expansion is the trigger to add cryptographic identity and the reliability module beforethe multi-agent version goes live — not after the first cascading-failure incident.
The maturity model
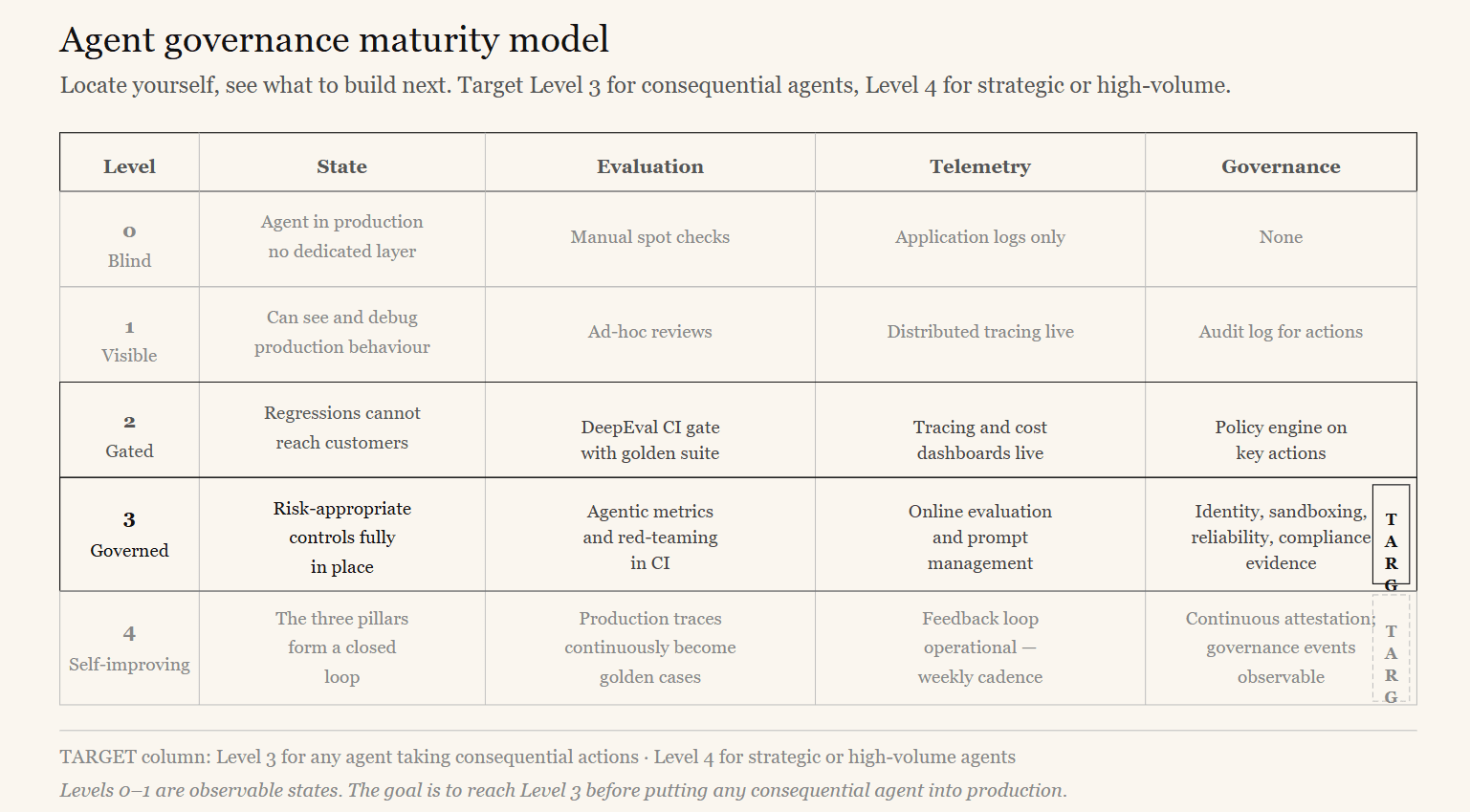
Organizations can locate themselves on this scale and see what to build next.
| Level | State | Evaluation | Telemetry | Governance |
|---|---|---|---|---|
| 0 — Blind | Agent in production, no dedicated layer | Manual spot checks | Application logs only | None |
| 1 — Visible | Can see and debug production behavior | Ad-hoc | Distributed tracing live | Audit log capturing actions |
| 2 — Gated | Regressions cannot reach customers | DeepEval CI gate with golden suite | Tracing and cost dashboards | Policy engine enforcing on key actions |
| 3 — Governed | Risk-appropriate controls fully in place | Agentic metrics and red-teaming in CI | Online evaluation and prompt management | Identity, sandboxing, reliability, compliance evidence |
| 4 — Self-improving | The three pillars form a closed loop | Production traces continuously become goldens | Feedback loop operational | Continuous compliance attestation; governance events observable |
Target Level 3 for any agent that takes consequential actions. Target Level 4 for strategic, high-volume agents.
The risks most teams underestimate

A few failure modes appear repeatedly across organizations adopting this architecture.
- Tool-overlap drift. Without a hard DeepEval-versus-Langfuse boundary, teams rebuild evaluation twice. Document the boundary in your internal golden-path guidance and do not let it blur.
- Deferring capability-triggered governance. Execution sandboxing and reliability controls are frequently and wrongly postponed as “scale-up” features. Tie them to explicit capability triggers — code execution; multi-agent — not to scale.
- The guardrails gap. Do not assume the three core tools cover runtime prompt-injection and PII filtering. They do not. Plan the fourth component explicitly.
- Mistaking the Microsoft product. Confirm at architecture-review time that “Microsoft agent governance” means the open-source toolkit — not the cloud-bound SaaS — if cloud-agnosticism is a requirement.
- Audit log versus trace store confusion. Observability traces are for debugging and are not tamper-evident. The governance audit log is the system of record. Keep the roles distinct.
- Evaluation cost. LLM-as-judge evaluation consumes model calls. Use smaller judge models and sampling for online evaluation; reserve expensive judges for the CI gate.
Summary
Build evaluation, telemetry, and governance as three best-of-breed layers connected by OpenTelemetry into a single feedback loop:
- DeepEval to keep regressions out.
- Langfuse to make production behavior visible.
- The Microsoft Agent Governance Toolkit to enforce, contain, identify, and prove.
An autonomous, non-deterministic system that takes real actions cannot be operated responsibly on the strength of any one of those alone.
This series synthesizes a reference architecture for evaluation, telemetry, and governance of agentic AI applications. Tool capabilities and version details evolve rapidly; treat the design patterns as durable and verify specific product features against current documentation before implementation.
Glossary
Agentic AI / AI agent
An AI system that does not merely answer questions but plans, makes decisions, and takes actions by calling tools, often over multiple steps and sometimes across multiple cooperating agents.
ADK (Agent Development Kit)
Google’s framework for building AI agents. It natively emits OpenTelemetry traces and exposes callback and plugin extension points.
OpenTelemetry (OTel)
An open, vendor-neutral standard for generating and collecting telemetry data (traces, metrics, logs). The common language that lets the tools in this architecture interoperate.
Trace / Span
A trace is the complete record of one agent run; a span is one step within it. Together they form a tree showing exactly what happened.
Golden dataset
A curated set of test inputs paired with expected outcomes, used as the regression suite for an agent.
Evaluation-as-a-CI-gate
The practice of running the evaluation suite automatically in the CI/CD pipeline and failing the build if quality drops below threshold.
LLM-as-judge
Using a language model to score the output of another model or agent against defined criteria.
Agentic metrics
Evaluation metrics specific to agent behavior: task completion, tool correctness, argument correctness, plan adherence, and task efficiency.
OWASP Agentic Security Initiative (ASI) Top 10
An industry-standard list of the top security risks specific to AI agents, used as the coverage checklist for the governance layer.
Policy engine
A deterministic, rule-based component that decides whether a proposed agent action is permitted, denied, or requires approval — before the action executes.
Decentralized identifier (DID) / mutual TLS / inter-agent trust
Mechanisms that give each agent a verifiable, non-spoofable identity and let agents authenticate each other before exchanging work.
Execution sandboxing
Running an agent’s code-executing tools in an isolated environment with constrained file-system, network, and resource access, so a bad action cannot reach beyond its intended boundary.
Circuit breaker / kill switch
Reliability controls that isolate a failing agent (circuit breaker) or halt an agent or fleet immediately (kill switch) to prevent cascading failure.
Tamper-evident audit log
An append-only log whose entries are cryptographically chained and signed, so any later alteration or deletion is detectable. The system of record for compliance.
Runtime content guardrails
Live inspection and filtering of the text entering and leaving the model on every request, to block prompt injection, jailbreaks, and personal-data leakage.