What Is Agentic AI, and Why Is It Harder to Govern?
How exactly are agents different from traditional software -- and why does that difference change what you need to build operationally?
6 min · Updated June 2026
Article 1 of 6 — “Governing AI Agents in the Enterprise: A Practical Architecture Guide”
The question at the top is not theoretical. The answer determines what kind of infrastructure you need to build, what can go wrong, and why the things that go wrong are often invisible until it is too late.

An AI agent is not a chatbot — and it is not traditional software
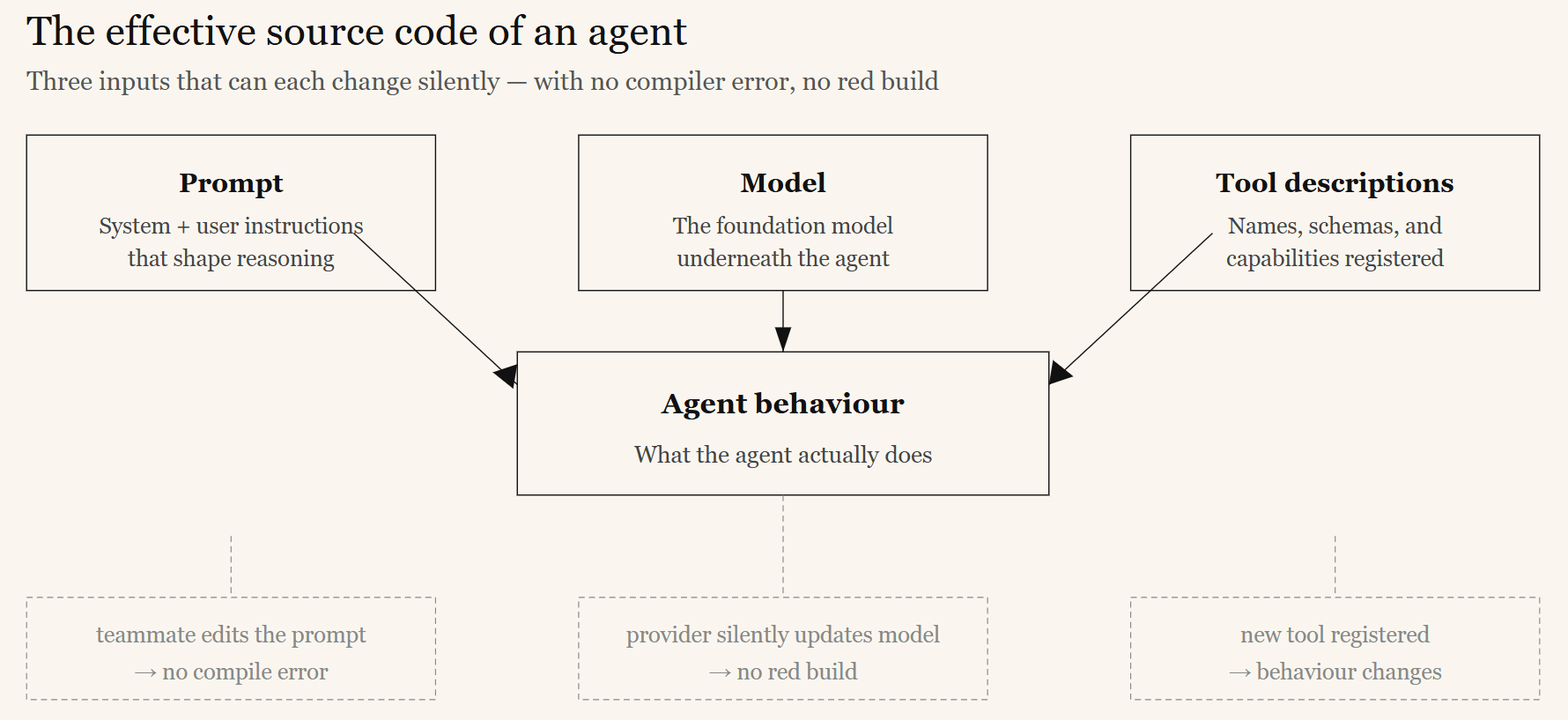
Traditional enterprise software is deterministic. You write the logic, you test it once, and — unless someone changes the code — it behaves identically forever. A failing test produces a red build. A bug has a stack trace.
A retrieval chatbot is a step removed from that. It generates language probabilistically, so responses vary, but it is still fundamentally reactive: it receives a question and produces an answer. The worst failure mode is a wrong sentence.
An AI agent breaks every one of those assumptions:
- Its behavior is non-deterministic. The same input can produce different reasoning paths and different actions on different runs — not because of a bug, but by design.
- Its “source code” changes underneath you. The effective behavior of an agent is determined by its prompt, the underlying model, and the tool descriptions it can call. A model provider can silently update a model. A teammate can edit a prompt. A new tool can be registered. None of these produces a compiler error — yet each can change behavior in ways that ripple across the whole application.
- It does not just answer — it acts. An agent calls tools: it queries databases, moves money, files claims, sends emails, provisions infrastructure, and executes code. The failure mode is no longer a wrong sentence — it is a wrong action against a real system.
- It is increasingly multi-agent. Modern agentic applications decompose work across specialist sub-agents that delegate to and call one another. Responsibility — and therefore accountability — diffuses across a graph of cooperating systems.
The combined effect: an agentic application can degrade, misbehave, or take an unauthorized action with no error, no log line, and no obvious cause. The discipline that catches a null-pointer exception will not catch an agent that has quietly become 15% worse at completing its task.
Three distinct questions — three distinct disciplines
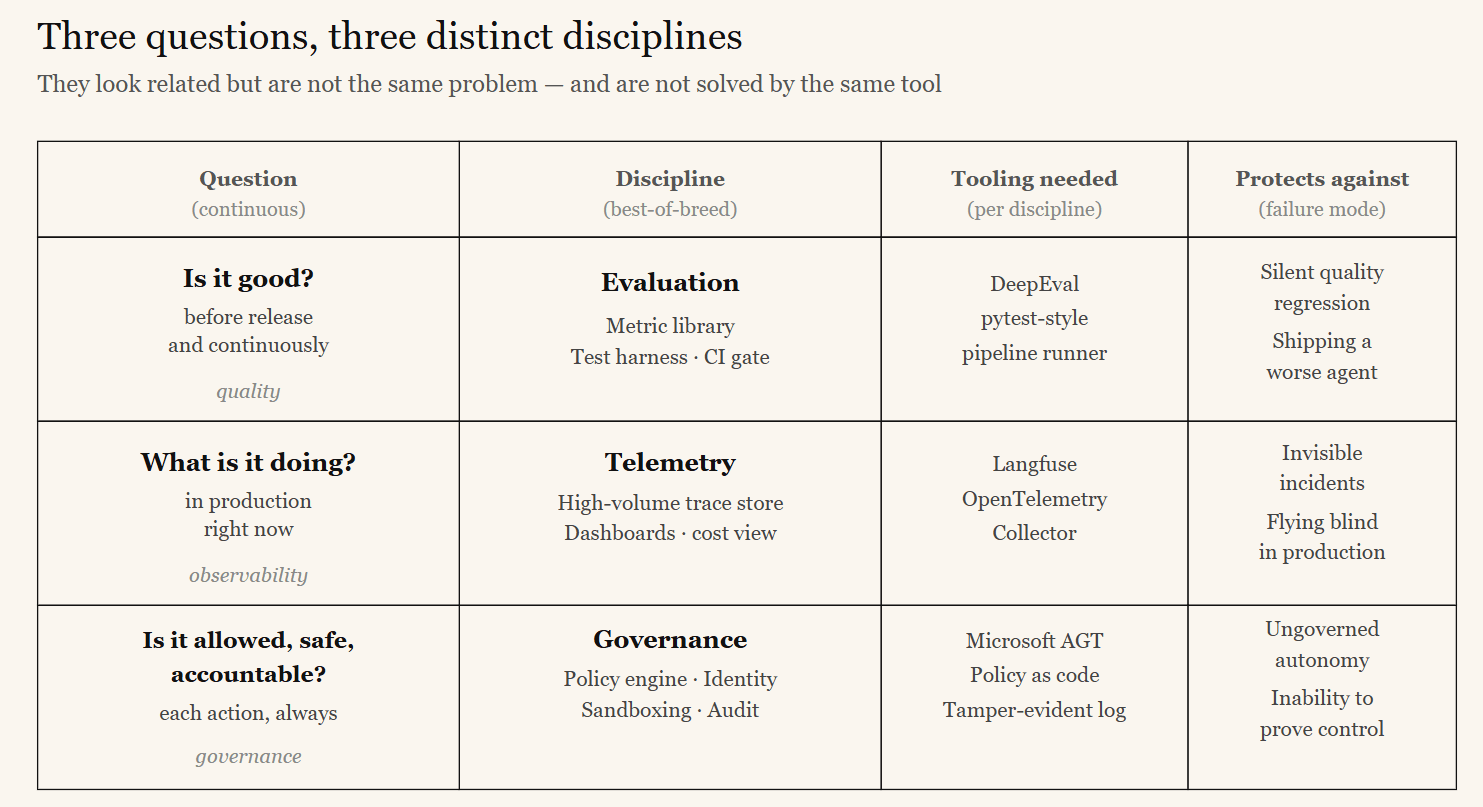
Operating an agent responsibly means continuously answering three questions. They look related, but they are not the same problem, and they are not solved by the same tool.
| Question | Discipline | Protects against |
|---|---|---|
| Is it good?— before release and continuously | Evaluation | Silent quality regression; shipping a worse agent |
| What is it doing? — in production, right now | Telemetry / Observability | Invisible incidents; flying blind |
| Is it allowed, safe, and accountable? | Governance | Ungoverned autonomy; unauthorized or unsafe actions; inability to prove control |
Evaluation asks whether the agent does its job well. It needs a metric library, a test harness, and a CI gate so that a regression fails a build the way a unit test does.
Telemetryasks what the agent is actually doing once real users are involved. It needs a high-volume trace store and dashboards — to see every reasoning step, tool call, latency spike, and cost line.
Governance asks whether each action is permitted, contained, identifiable, and provable. It needs deterministic policy enforcement, cryptographic agent identity, execution isolation, and tamper-evident audit.
These are differently shaped problems. Trying to make one tool do all three produces a system that is mediocre at each, has unclear ownership, and creates a single point of failure. The right architecture uses a best-of-breed tool per discipline, connected by an open standard.
What skipping this costs
Organizations that deploy agents without this layer typically discover the gap the expensive way.
Silent quality decay.An agent is launched, works well, and is left alone. Months later, customer churn or complaint volume rises. Nobody can say when the agent got worse, by how much, or why — because nobody was measuring.
Invisible incidents.An agent does something harmful. Support escalates it. Engineering cannot reconstruct what the agent saw, which tools it called, or why it decided what it decided — because the run was never traced.
Ungoverned autonomy. An agent takes an action no policy ever authorized. There is no record of what controls were in place, so the organization cannot demonstrate due diligence to a regulator, an auditor, or a court.
There is also a regulatory clock. The EU AI Act and sector regulators in banking, healthcare, insurance, and the public sector increasingly expect organizations to demonstrategovernance over AI systems that make or influence decisions. “We tested it once before launch” is not a defense. Evidence is.
The key architectural principle: a loop, not three silos
The most important idea in this entire series: evaluation, telemetry, and governance are not three separate projects. They are one system with a feedback loop.
- Telemetry feeds evaluation. Real production traces — especially the surprising, low-scoring, or expensive ones — become the next round of test cases.
- Evaluation feeds governance. Evaluation thresholds become release gates; an agent that fails them does not ship.
- Governance feeds telemetry. Every policy decision the governance layer makes is itself an observable event that flows into the same dashboards.
When the three are wired into a loop, the agent gets measurably safer and better over time. When they are three disconnected tools owned by three teams, they generate three dashboards nobody reconciles.
The reference stack used throughout this series
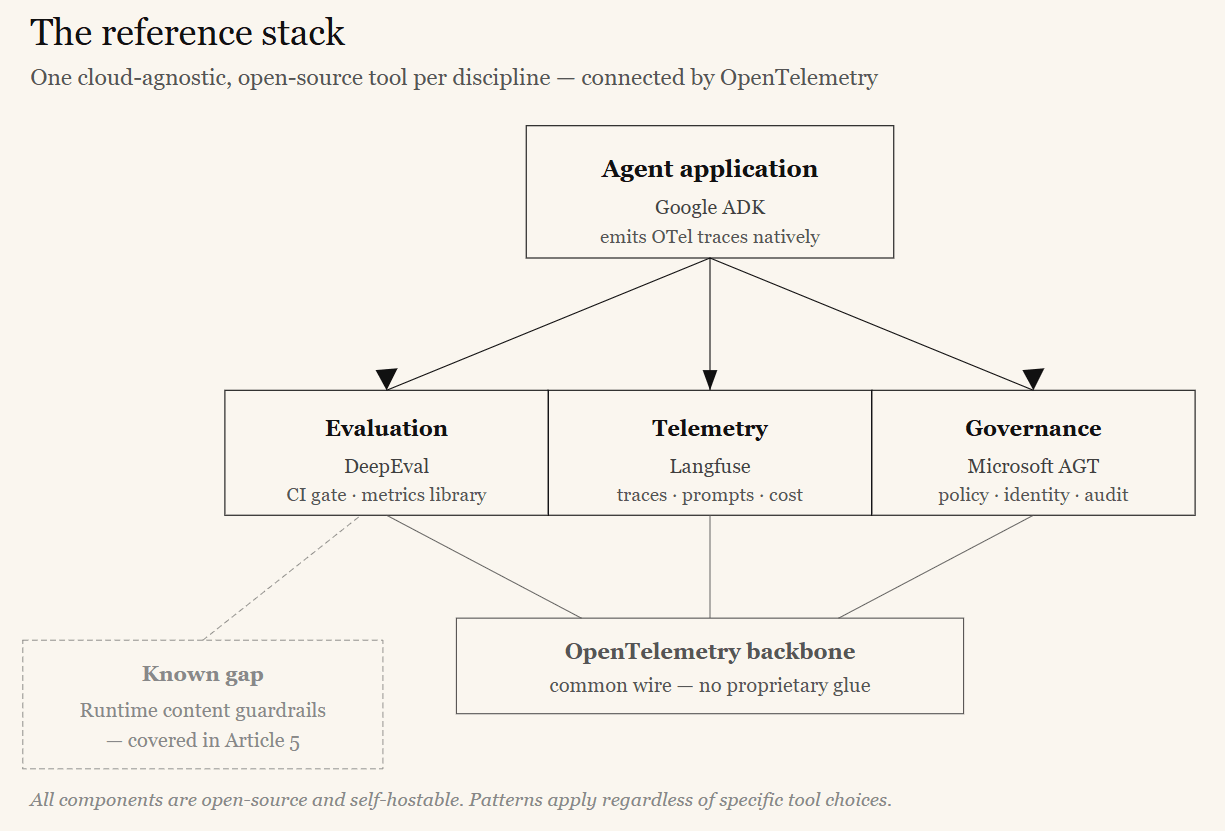
The rest of this series uses one concrete, cloud-agnostic stack to illustrate each pattern. All components are open-source and self-hostable.
- Agent framework — Google ADK. The agent application. ADK natively emits OpenTelemetry traces and exposes lifecycle callbacks and a plugins system — the extension points the other tools attach to.
- Evaluation — DeepEval. An open-source evaluation framework with a large library of research-backed metrics, including agent-specific ones. It runs as a pytest-style CI gate.
- Telemetry — Langfuse. An open-source LLM observability platform. Self-hostable, it ingests OpenTelemetry traces, manages prompt versions, stores datasets, and runs lightweight online evaluations.
- Governance — Microsoft Agent Governance Toolkit (AGT). An open-source toolkit of governance modules: a policy engine, cryptographic agent identity, execution sandboxing, reliability engineering, and compliance evidence. Framework- and cloud-agnostic.
- Backbone — OpenTelemetry. The open standard that lets all of the above exchange trace data without proprietary glue.
One known gap: none of the three core tools fully covers runtime content guardrails — inspecting and filtering the live text flowing in and out of the model to block prompt injection or PII leakage. That requires an explicit fourth component, addressed in Article 5.