Why Your AI Agent Isn't Safe Yet
Preface to the series: “Governing AI Agents in the Enterprise: A Practical Architecture Guide”
3 min · Updated June 2026
You’ve shipped an AI agent. Or you’re about to. Maybe it handles customer queries. Maybe it books travel, processes claims, pulls data from your systems, or drafts communications on behalf of your team. Maybe it does all of this on its own, without a human approving every step.
If any of that sounds familiar, this series is for you — and there’s a good chance you have a problem you haven’t fully measured yet.
What most teams discover too late
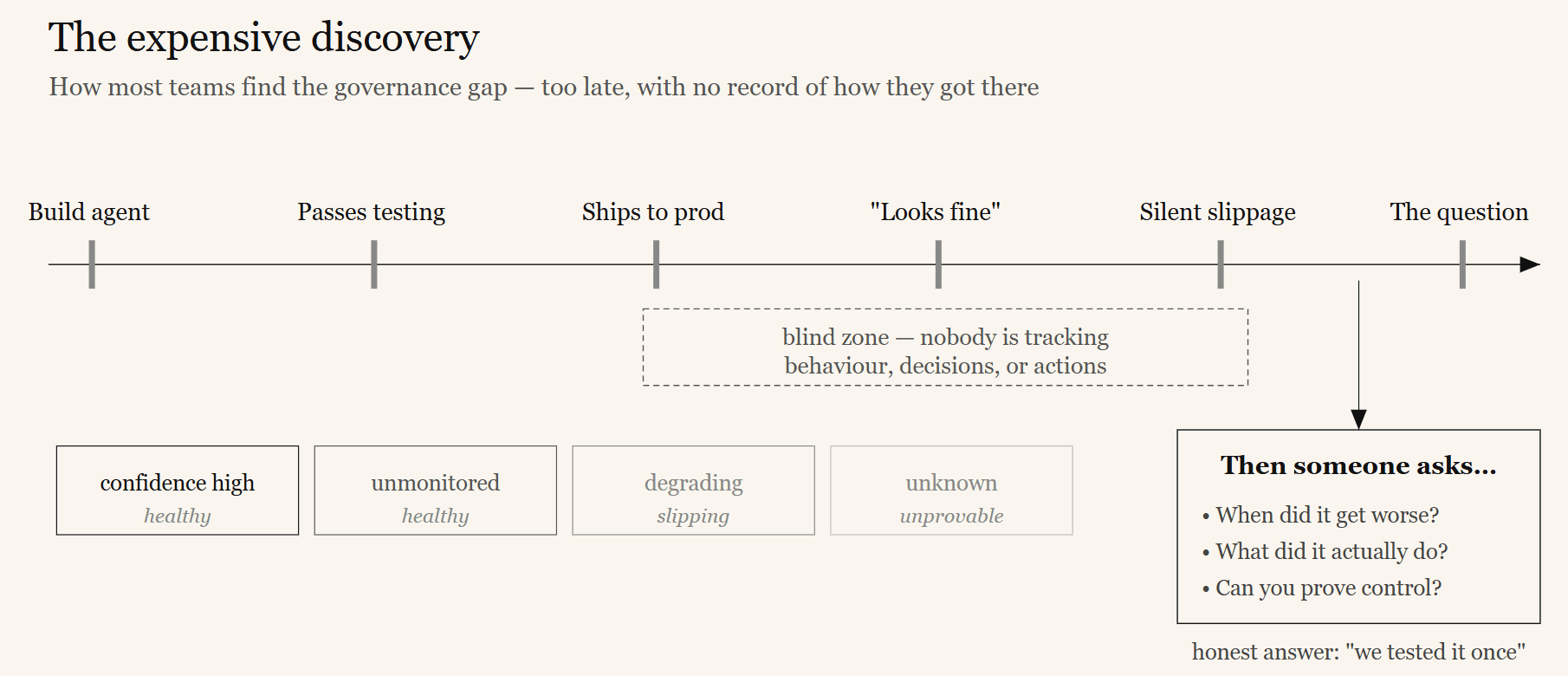
Here is what typically happens. A team builds an agent. It works well in testing. It goes to production. For a while, everything looks fine. Then, quietly, things start to slip.
A customer complains that the agent gave them the wrong guidance — but nobody can say when the agent started doing that, or why, because nobody was tracking it. A support ticket comes in where the agent clearly did something it should not have — but there is no log of what it saw, what it decided, or which tool it called. A regulator asks your compliance team to demonstrate that the agent is operating within defined controls — and the honest answer is: we tested it before launch, but we cannot prove anything about what it has been doing since.
None of this is carelessness. It is a structural gap that almost every team hits, because AI agents require a different kind of operational discipline than the software we have been building for decades.
What makes agents different

Traditional software is predictable. You write the logic, you test it, and it does the same thing every time. When something breaks, there is an error log.
An AI agent does not work that way:
- Its behavior can vary from run to run, even with the same input.
- Its effective “source code” is its prompt and the model underneath it — both of which can change without anyone touching the application’s source code.
- It does not just answer questions. It acts— it calls tools, reads and writes data, moves things, and triggers workflows in real systems.
- Increasingly, it coordinates with other agents — handing off work, receiving instructions, acting on behalf of systems it cannot fully verify.
A traditional test suite will not catch an agent that has quietly gotten 15% worse at its job. An error log will not tell you why an agent took an action nobody authorized. And “we tested it before launch” is not a governance posture — it is a one-time event.
The three questions you need to be able to answer — always
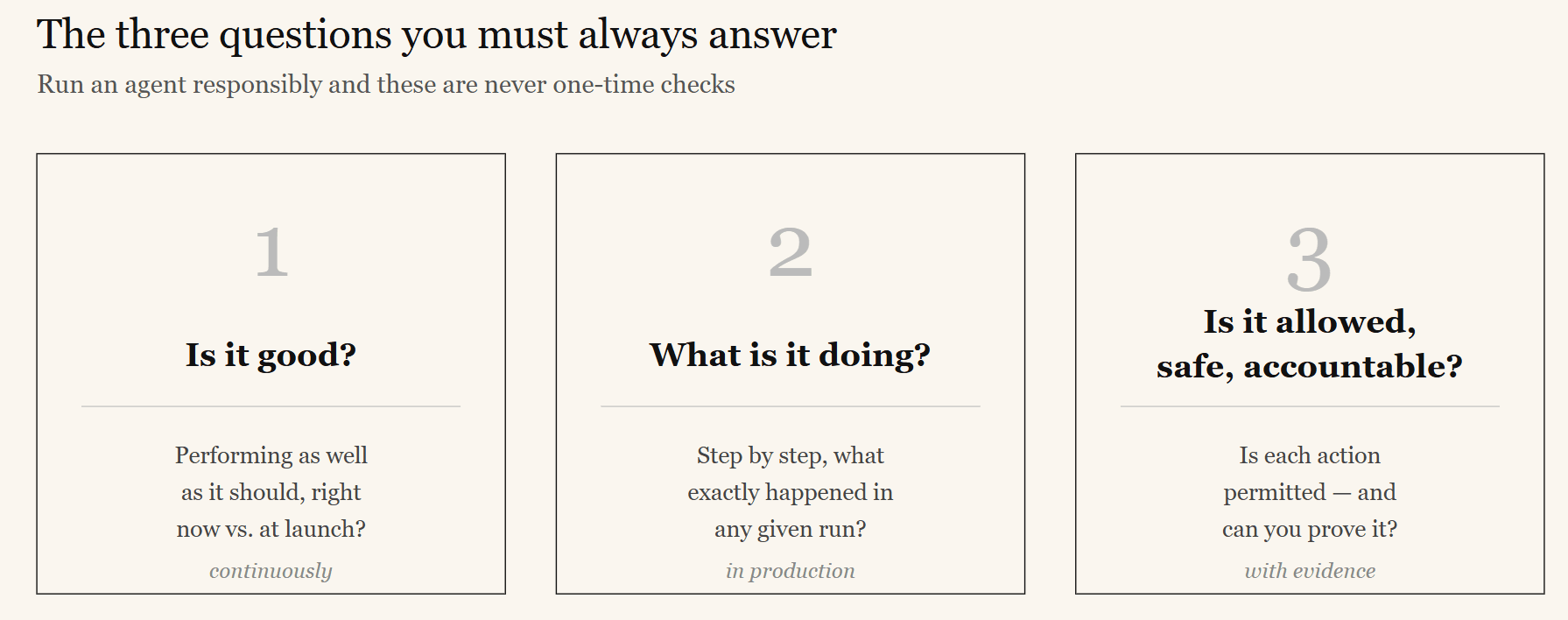
Running an agent responsibly means continuously being able to answer three questions:
- 1.Is it good?— Is the agent performing as well as it should, right now, compared to when it launched?
- 2.What is it doing?— What exactly happened in any given agent run, step by step, in production?
- 3.Is it allowed, safe, and accountable? — Is each action the agent takes permitted? Can you prove it?
Most teams cannot answer any of these — not because they are negligent, but because they have not yet built the layer of tooling that makes these questions answerable. That is what this series is about.
What this series covers
This is a practical, architecture-level guide to building evaluation, telemetry, and governance for enterprise AI agents. It is written for the people who actually build and operate these systems: engineers, architects, AI/ML leads, risk and compliance officers, and product owners.
It is structured around 14 real questions from enterprise architecture reviews — the kind that do not have easy answers until you have thought through the design patterns behind them. Each article takes a cluster of those questions and answers them directly, with a concrete reference architecture and real-world examples across industries.
The tools discussed throughout — DeepEval (evaluation), Langfuse (observability), and the Microsoft Agent Governance Toolkit (governance), wired together with OpenTelemetry— are all open-source and cloud-agnostic. The patterns, however, apply regardless of what specific tools you choose.
How to read this series
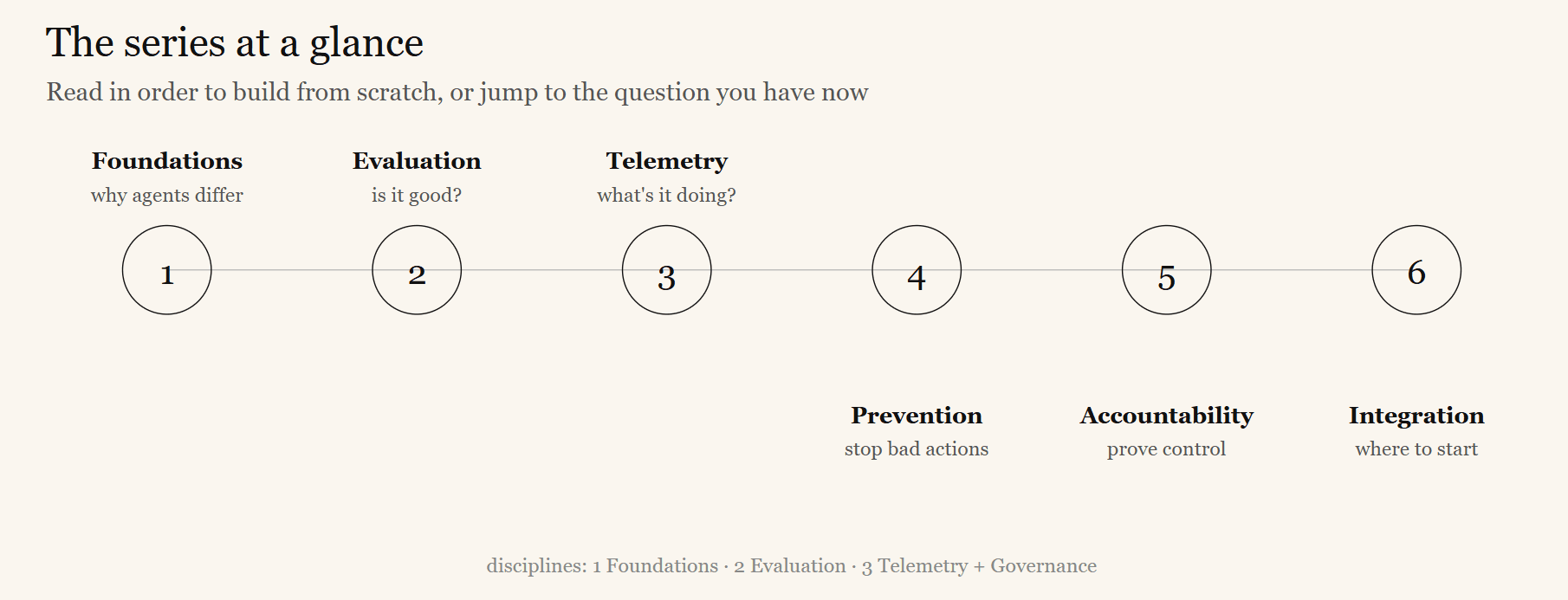
Read it in order if you are building or redesigning your agent infrastructure from scratch. Jump to specific articles if you have an immediate question:
- Article 1: What Is Agentic AI, and Why Is It Harder to Govern? — The core problem and the three disciplines explained.
- Article 2: How Do You Know Your Agent Is Good? — Evaluation and regression testing for agents.
- Article 3: How Do You See What Your Agent Is Doing in Production? — Distributed tracing, observability, and prompt management.
- Article 4: How Do You Stop Agents from Doing Dangerous Things? — Policy enforcement, agent identity, sandboxing, and reliability.
- Article 5: How Do You Prove Your Agents Are Governed? — Audit, compliance evidence, guardrails, and tool ownership.
- Article 6: How Do You Tie It All Together — and Where Do You Start? — Integration, maturity model, and a sequenced adoption plan.
This series synthesizes a reference architecture for evaluation, telemetry, and governance of agentic AI. Design patterns are durable; specific tool capabilities evolve — verify current documentation before implementation.